合并访存与 Bank Conflict
transpose算子与合并访存
transpose算子的实现
transpose,即矩阵的转置,最简单的实现没啥好说的,直接看代码吧。
__global__ void transpose_v1(float* output, float* input, int nx, int ny){
int id_x = threadIdx.x + blockIdx.x * blockDim.x;
int id_y = threadIdx.y + blockIdx.y * blockDim.y;
if (id_x >= nx || id_y >= ny) return;
output[id_x * ny + id_y] = input[id_y * nx + id_x];
}
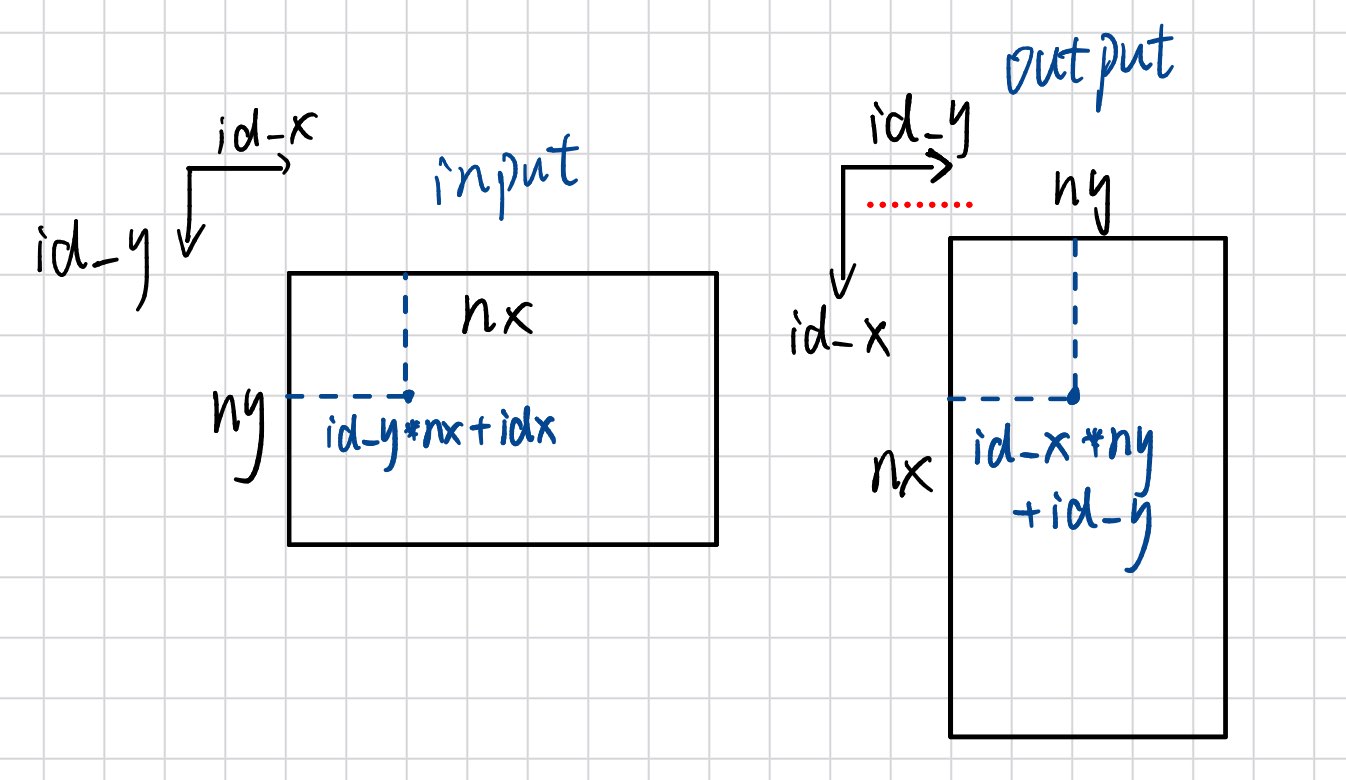
唯一需要注意的地方就是坐标的映射,图里已经画的很清楚了。
实现的方法不是重点,重点在于借这个核函数来理解合并访存。
什么是合并访存?
首先我们要知道,GPU里一次内存事务的最小访问单位是sector(32B),当线程需要某个数据时,不是只将这一个数据调入,而是将这个数据所在的整个sector调入。
如下图所示,一个共有32个线程的warp访问显存,每个线程需要访问一个float(4B)
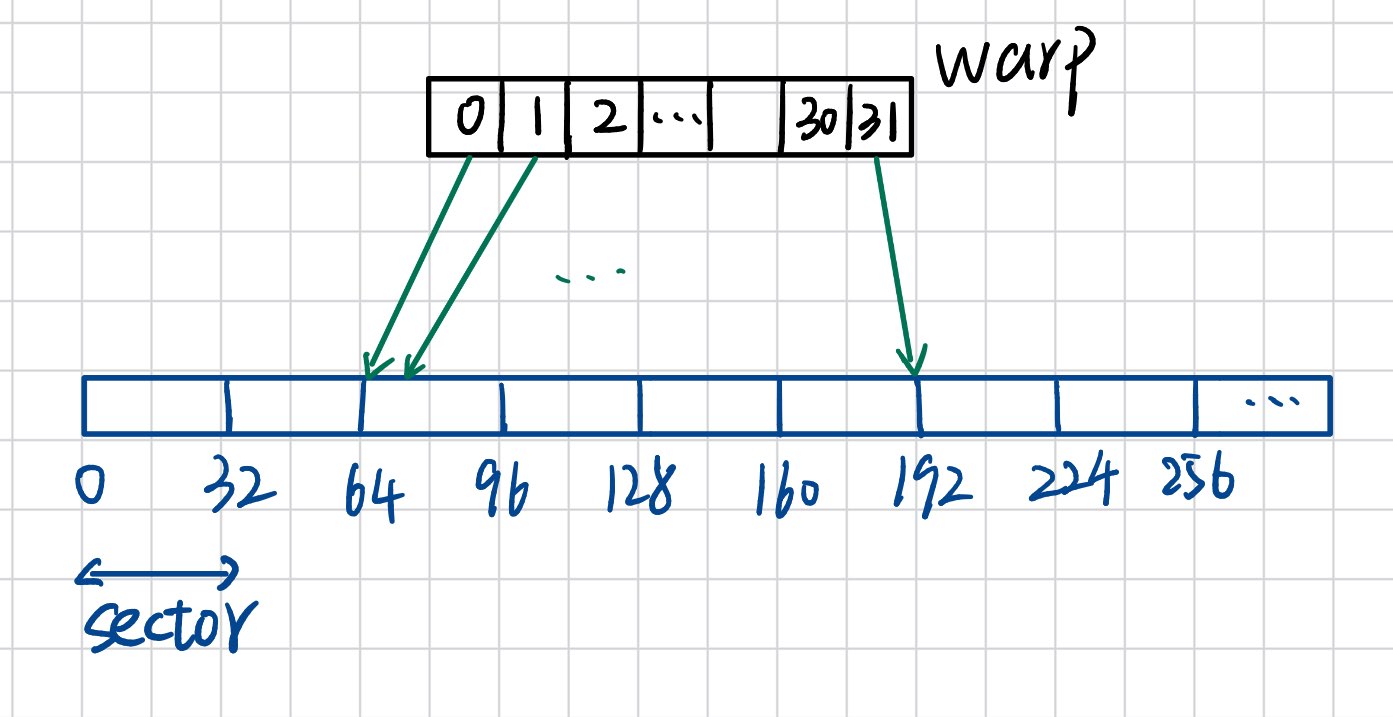
如果0号线程访问的地址恰好是32的整数倍(如图),那整个sector的数据都会用上,恰好读入4个sector。这种情况就是合并访存。
例子看完了,再来看看合并访存的定义:合并访问指的是一个线程束对全局内存的一次访问请求(读或写)导致最少数量的数据传输;否则称访问是非合并的。
下面再看看非合并访存的例子:
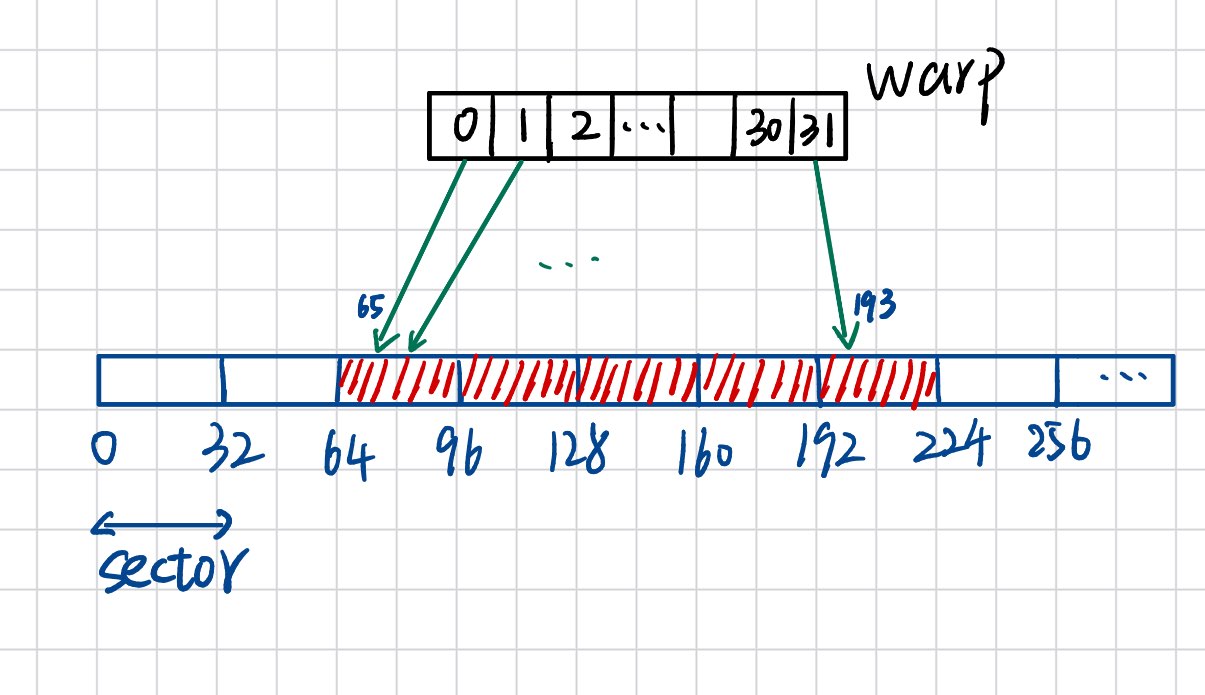
0号线程访问的地址是65,这就导致需要读入5个sector。而最后读入的那个sector大部分的数据都是不需要的,这就降低了访存的效率。
通过这种思路,我们如何来设计高效的transpose算子呢?
假设我们设置block大小为(32,8),每个线程读一个float(4B):
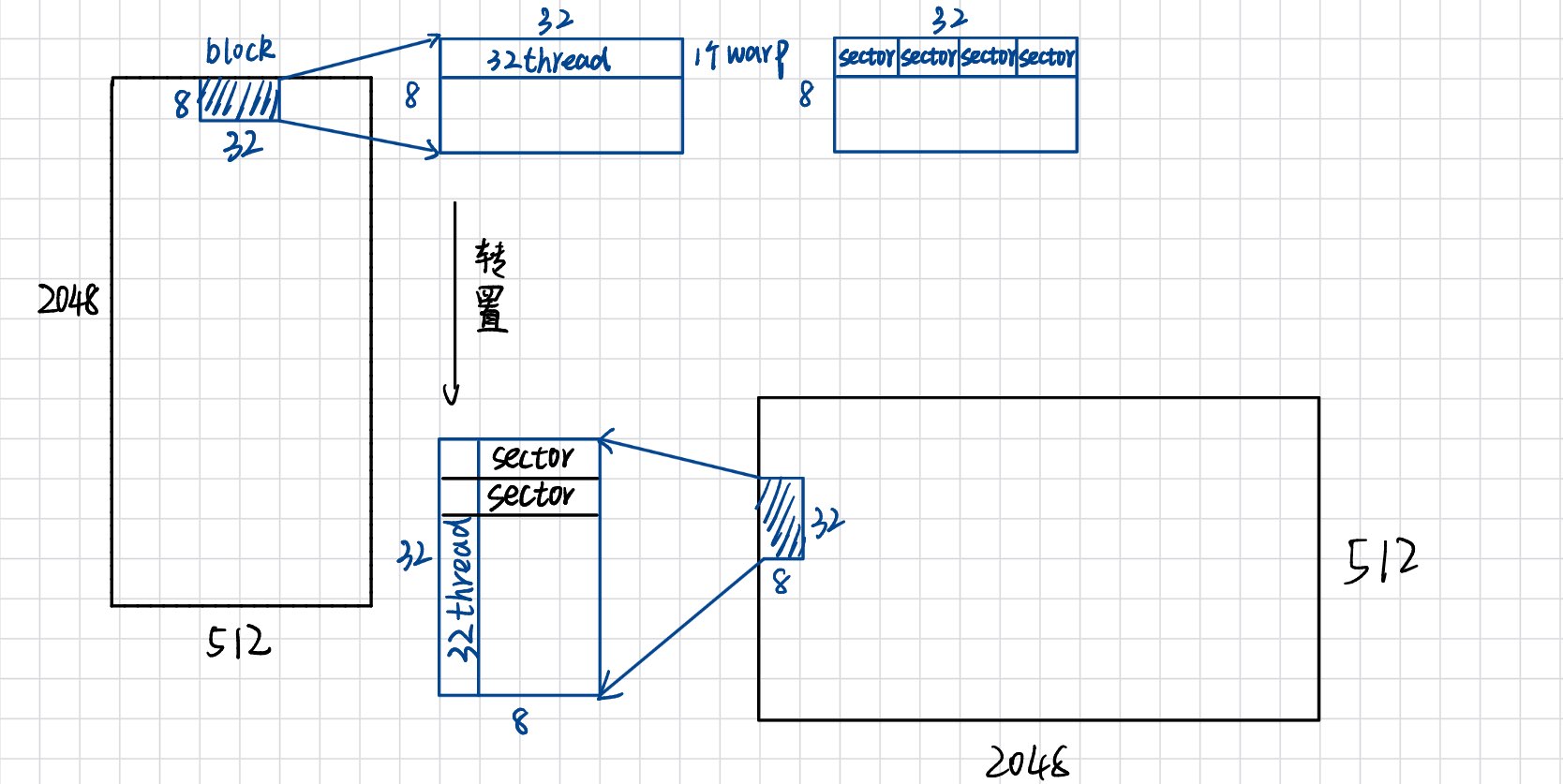
在read的时候,这就是完美的合并访存,一个warp刚好读入4个sector,数据不多也不少。
但是在write的时候,就出现问题了。由图可以很清晰地看到,每写入一个数据就得读整个sector,总共要读32个sector,效率大大降低。
那如果把block设置为(8,32)呢?
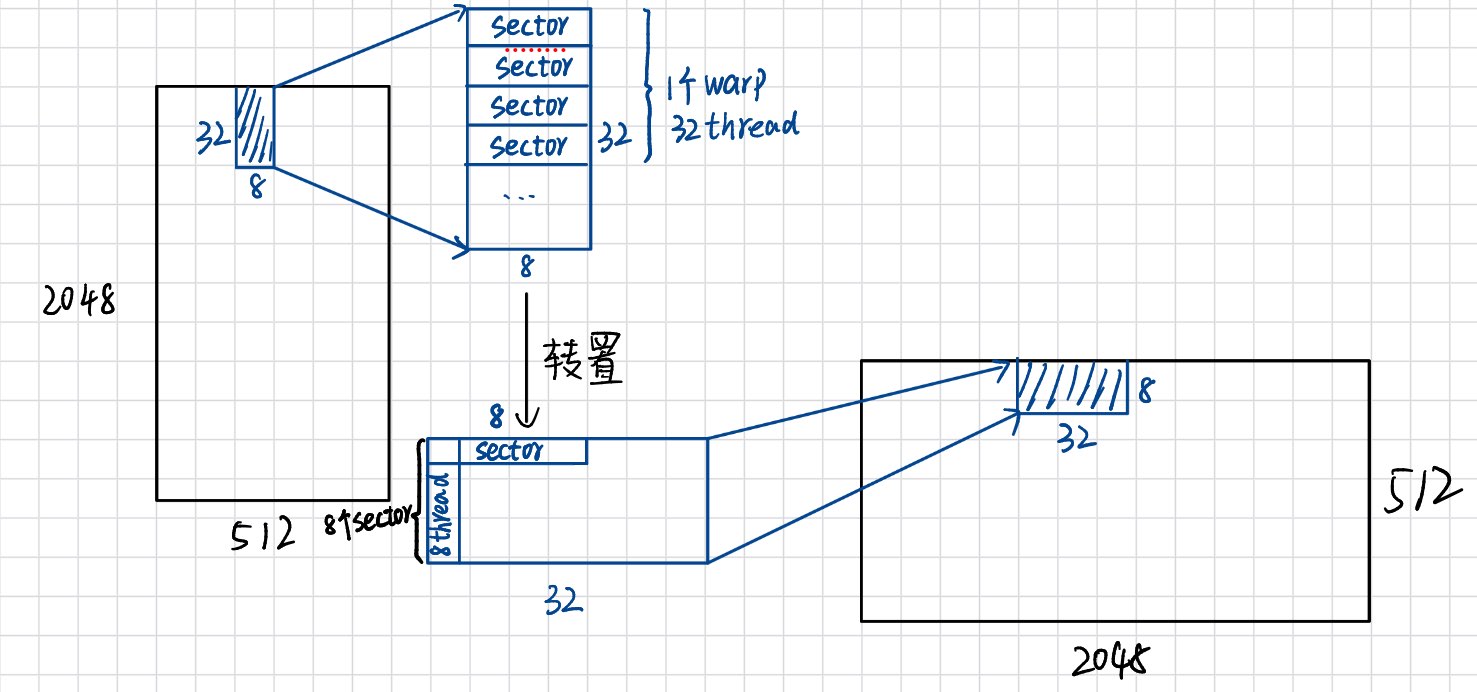
可以看到,在read阶段,正好读入4个sector
转置后,在write阶段则需要读入8个sector,相比之前的32个sector已经有了很大提升。
naive实现
我们来通过代码看看这两种不同的block大小设置的差异。
v1核函数与调用函数:
__global__ void transpose_v1(float* output, float* input, int nx, int ny){
int id_x = threadIdx.x + blockIdx.x * blockDim.x;
int id_y = threadIdx.y + blockIdx.y * blockDim.y;
if (id_x >= nx || id_y >= ny) return;
output[id_x * ny + id_y] = input[id_y * nx + id_x];
}
void call_v1(float* d_output, float* d_input, int nx, int ny, int BLKDIM_x, int BLKDIM_y){
dim3 blockSize(BLKDIM_x, BLKDIM_y);
dim3 gridSize((nx + blockSize.x - 1) / blockSize.x, (ny + blockSize.y - 1) / blockSize.y);
transpose_v1<<<gridSize, blockSize>>>(d_output, d_input, nx, ny);
}
v1的计时函数:
float* v1_time(int nx, int ny, int warmup, int repeat_time, int BLKDIM_x, int BLKDIM_y){
int elemCount = nx * ny;
int numBytes = elemCount * sizeof(float);
float* h_input,* h_output;
h_input = (float*)malloc(numBytes);
h_output = (float*)malloc(numBytes);
for (int i = 0; i < elemCount; i++){
h_input[i] = float(i);
}
float* d_input,* d_output;
cudaMalloc((void**)&d_input, numBytes);
cudaMalloc((void**)&d_output, numBytes);
cudaMemcpy(d_input, h_input, numBytes, cudaMemcpyHostToDevice);
for (int i = 0; i < warmup; i++){
call_v1(d_output, d_input, nx, ny, BLKDIM_x, BLKDIM_y);
}
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start);
for (int i = 0; i < repeat_time; i++){
call_v1(d_output, d_input, nx, ny, BLKDIM_x, BLKDIM_y);
}
cudaEventRecord(end);
cudaEventSynchronize(end);
float v1_time = 0;
cudaEventElapsedTime(&v1_time, start, end);
std::cout << "blockdim:(" << BLKDIM_x << "," << BLKDIM_y << ")" << std::endl;
std::cout << "v1 time:" << v1_time << "ms" << std::endl;
std::cout << "---------------------" << std::endl;
cudaDeviceSynchronize();
cudaMemcpy(h_output, d_output, numBytes, cudaMemcpyDeviceToHost);
cudaEventDestroy(start);
cudaEventDestroy(end);
cudaFree(d_output);
cudaFree(d_input);
free(h_input);
return h_output;
}
判断结果是否相等:
bool isMatch(float* a, float* b, int elemCount){
for (int i = 0; i < elemCount; i++){
if (fabsf(a[i] - b[i]) > 1e-5) return false;
}
return true;
}
cpu实现transpose:
float* transpose_cpu(float* output, int nx, int ny){
float input[nx * ny];
for (int i = 0; i < nx * ny; i++){
input[i] = float(i);
}
for (int i = 0; i < ny; i++){
for (int j = 0; j < nx; j++){
// output[j][i] = input[i][j];
output[j * ny + i] = input[i * nx + j];
}
}
return output;
}
main函数:
int main(){
int nx = 4096, ny = 4096;
int numBytes = nx * ny * sizeof(float);
float* cpu_output = (float*)malloc(numBytes);
cpu_output = transpose_cpu(cpu_output, nx, ny);
float* v1_output1 = v1_time(nx, ny, 10, 10, 8, 32);
float* v1_output2 = v1_time(nx, ny, 10, 10, 32, 8);
if (isMatch(cpu_output, v1_output1, nx * ny)){
std::cout << "Results1 Match!" << std::endl;
}
else{
std::cout << "Results1 not Match!" << std::endl;
}
if (isMatch(cpu_output, v1_output2, nx * ny)){
std::cout << "Results2 Match!" << std::endl;
}
else{
std::cout << "Results2 not Match!" << std::endl;
}
}
执行结果:
blockdim:(8,32)
v1 time:7.20179ms
---------------------
blockdim:(32,8)
v1 time:17.0895ms
---------------------
Results1 Match!
Results2 Match!
在nsight compute中:

(8,32)
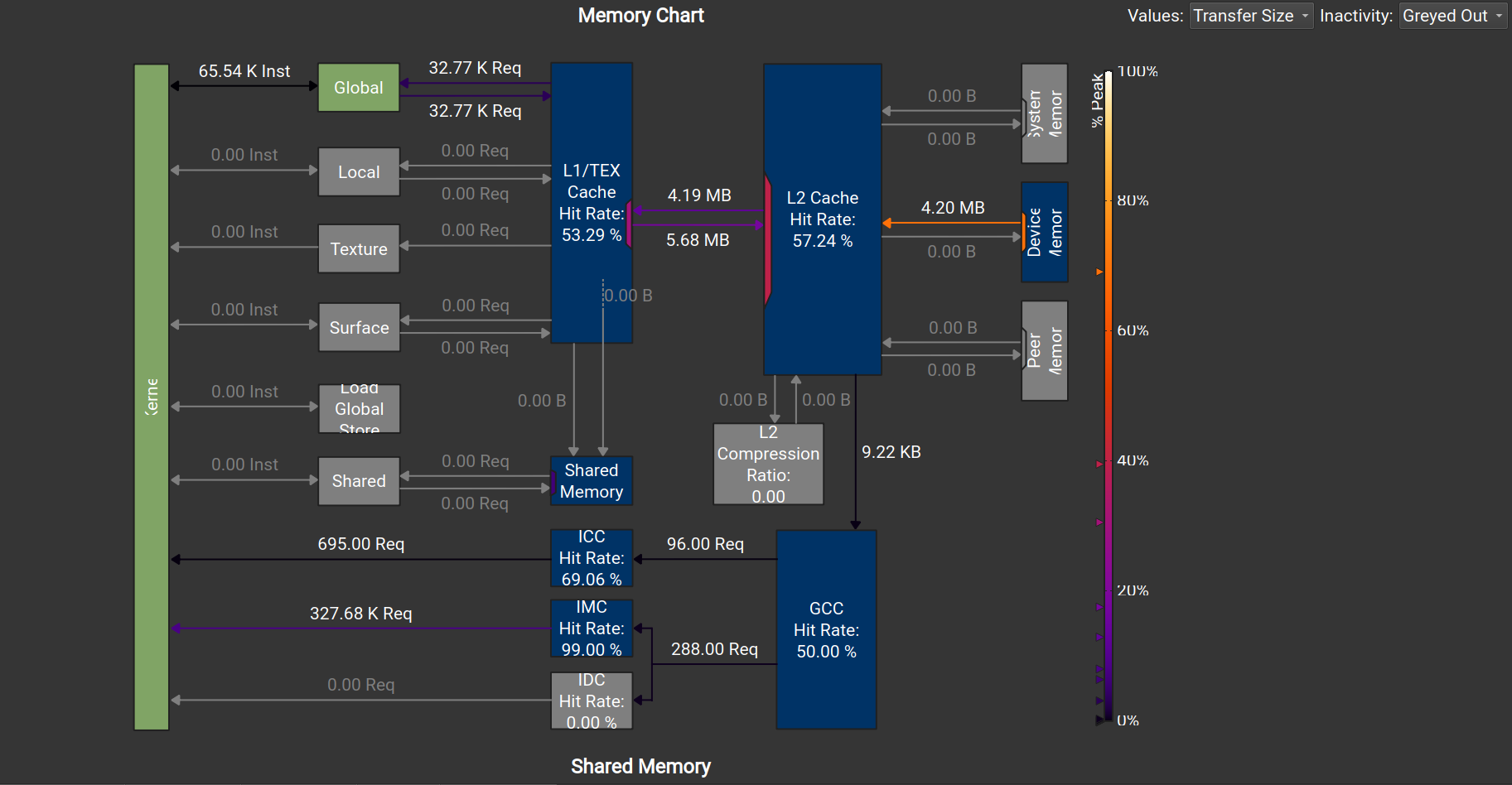

我们关注Global Load 和 Global Store的Sectors/Request(每个请求对应的扇区数)
在Load阶段为4,即一个 Warp(32 线程)总共需要 $32 \times 4 = 128$ 字节。这正好对应 4 个扇区。访存是完全合并的。
在Store阶段为8,这与我们前面的分析完全相同。
(32,8)
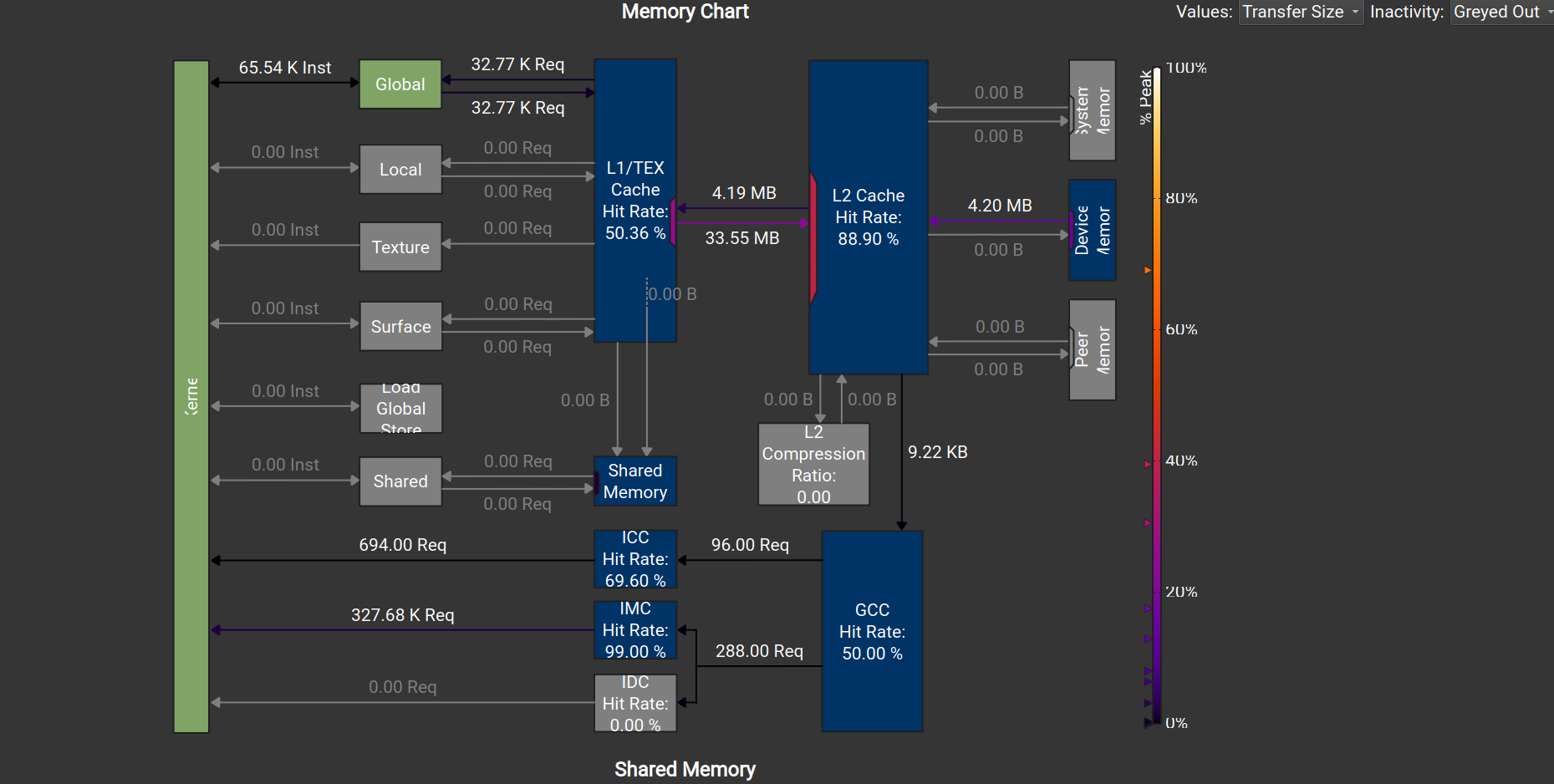

在write过程中,可以看到L1 cache -> L2 cache过程中,后者的数据传输量更大。这就是因为非合并访存读入了更多的sector。
在Global Load阶段,Sectors/Request 仍然是4
在Global Store阶段,变成了32,即非合并访存,这也证实了我们之前的分析。
向量化访存
和矩阵乘法里用到的优化方法相同,我们让一个线程一次性取四个数据。
input -> src -> dst -> output
#define FETCH_FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
template <const int THREAD_SIZE_Y, const int THREAD_SIZE_X>
__global__ void transpose_v2(float* output, float* input, int M, int N){
float src[4][4];
float dst[4][4];
float* input_start = blockIdx.y * THREAD_SIZE_Y * N + blockIdx.x * THREAD_SIZE_X + input;
for (int i = 0; i < 4; i++){
FETCH_FLOAT4(src[i]) = FETCH_FLOAT4(input_start[(threadIdx.y * 4 + i) * N + threadIdx.x * 4]);
}
FETCH_FLOAT4(dst[0]) = make_float4(src[0][0], src[1][0], src[2][0], src[3][0]);
FETCH_FLOAT4(dst[1]) = make_float4(src[0][1], src[1][1], src[2][1], src[3][1]);
FETCH_FLOAT4(dst[2]) = make_float4(src[0][2], src[1][2], src[2][2], src[3][2]);
FETCH_FLOAT4(dst[3]) = make_float4(src[0][3], src[1][3], src[2][3], src[3][3]);
float* output_start = blockIdx.x * THREAD_SIZE_X * M + blockIdx.y * THREAD_SIZE_Y + output;
for (int i = 0; i < 4; i++){
FETCH_FLOAT4(output_start[(threadIdx.x * 4 + i) * M + threadIdx.y * 4]) = FETCH_FLOAT4(dst[i]);
}
}
input_start的坐标计算如图所示:
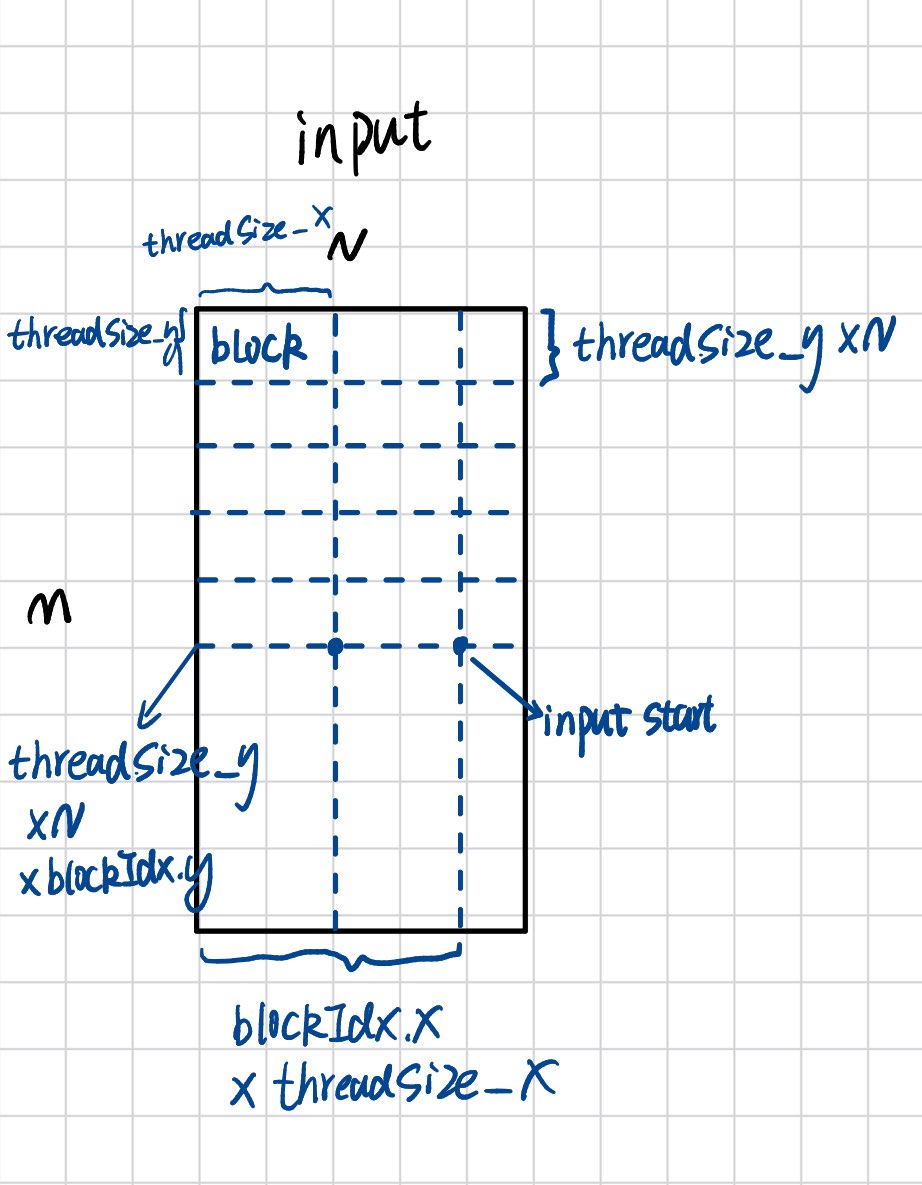
output_start也是同理。
至于这里:
FETCH_FLOAT4(input_start[(threadIdx.y * 4 + i) * N + threadIdx.x * 4]);
为什么threadIdx要乘4?是因为一个线程在一个维度上负责4个数据。
比如在x维度:
0号线程负责0,1,2,3
1号线程负责4,5,6,7
2号线程负责8,9,10,11
…
则0号线程负责的数据起始地址就是0x4=0
1号线程负责的数据起始地址就是1x4=4
2号线程负责的数据起始地址就是2x4=8
…
核函数的实现我们弄清楚了,接下来看看如何配置线程块的大小来实现合并访存。
如果配置成(32,8),那每个block负责的数据块大小则是32x128
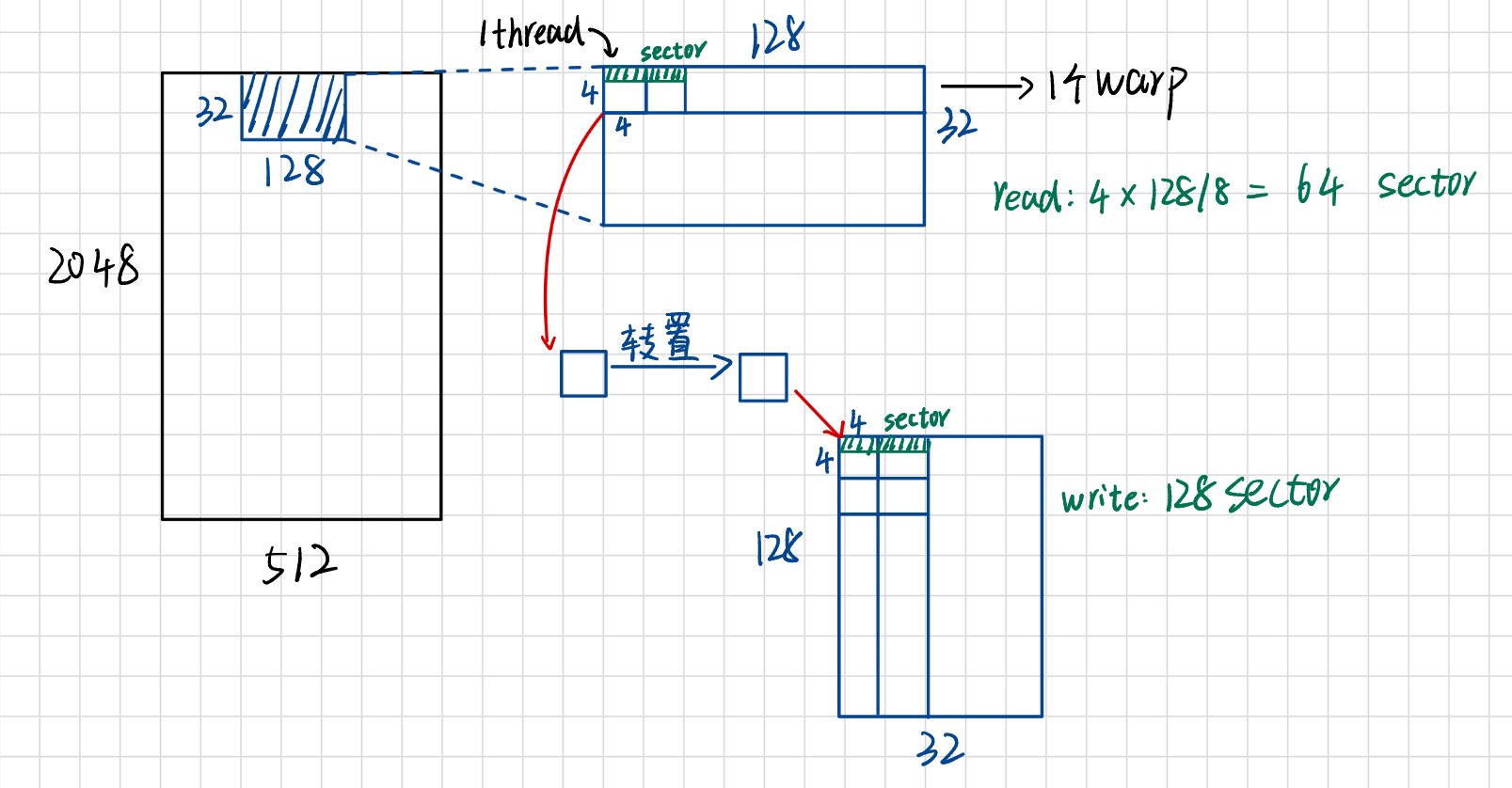
由图可以看出,read阶段是合并访存,只需要读64个sector;而write阶段属于非合并访存,需要读128个sector。每次读入的sector只有一半的数据是有效的。
如果配置成(16,16),则都可以实现合并访存。
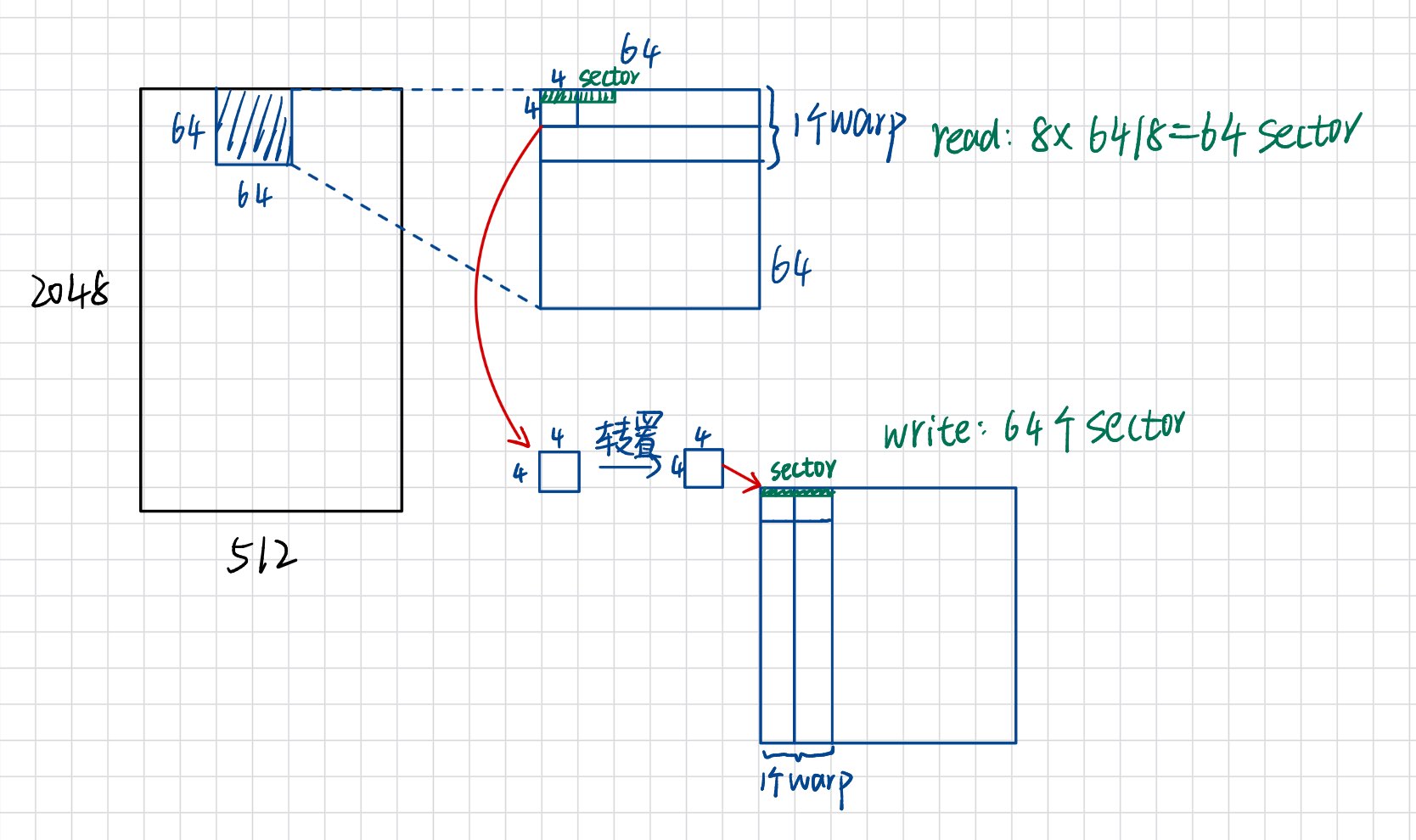
由图可知,在write阶段读入的sector所有数据都是有效的。
整体代码:
#include<iostream>
#include"cuda_runtime.h"
float* transpose_cpu(float* output, int nx, int ny){
float input[nx * ny];
for (int i = 0; i < nx * ny; i++){
input[i] = float(i);
}
for (int i = 0; i < ny; i++){
for (int j = 0; j < nx; j++){
// output[j][i] = input[i][j];
output[j * ny + i] = input[i * nx + j];
}
}
return output;
}
#define FETCH_FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
template <const int THREAD_SIZE_Y, const int THREAD_SIZE_X>
__global__ void transpose_v2(float* output, float* input, int M, int N){
float src[4][4];
float dst[4][4];
float* input_start = blockIdx.y * THREAD_SIZE_Y * N + blockIdx.x * THREAD_SIZE_X + input;
for (int i = 0; i < 4; i++){
FETCH_FLOAT4(src[i]) = FETCH_FLOAT4(input_start[(threadIdx.y * 4 + i) * N + threadIdx.x * 4]);
}
FETCH_FLOAT4(dst[0]) = make_float4(src[0][0], src[1][0], src[2][0], src[3][0]);
FETCH_FLOAT4(dst[1]) = make_float4(src[0][1], src[1][1], src[2][1], src[3][1]);
FETCH_FLOAT4(dst[2]) = make_float4(src[0][2], src[1][2], src[2][2], src[3][2]);
FETCH_FLOAT4(dst[3]) = make_float4(src[0][3], src[1][3], src[2][3], src[3][3]);
float* output_start = blockIdx.x * THREAD_SIZE_X * M + blockIdx.y * THREAD_SIZE_Y + output;
for (int i = 0; i < 4; i++){
FETCH_FLOAT4(output_start[(threadIdx.x * 4 + i) * M + threadIdx.y * 4]) = FETCH_FLOAT4(dst[i]);
}
}
template <const int BLKDIM_x, const int BLKDIM_y>
void call_v2(float* d_output, float* d_input, int M, int N){
dim3 blockSize(BLKDIM_x, BLKDIM_y); // 每个线程块有 32x8 = 256 个线程
constexpr int THREAD_SIZE_X = BLKDIM_x * 4; // 每个 block 处理 128 列
constexpr int THREAD_SIZE_Y = BLKDIM_y * 4; // 每个 block 处理 32 行
dim3 gridSize(
(N + THREAD_SIZE_X - 1) / THREAD_SIZE_X,
(M + THREAD_SIZE_Y - 1) / THREAD_SIZE_Y
);
transpose_v2<THREAD_SIZE_Y, THREAD_SIZE_X><<<gridSize, blockSize>>>(d_output, d_input, M, N);
}
template <const int BLKDIM_x, const int BLKDIM_y>
float* v2_time(int M, int N, int warmup, int repeat_time){
int elemCount = M * N;
int numBytes = elemCount * sizeof(float);
float* h_input,* h_output;
h_input = (float*)malloc(numBytes);
h_output = (float*)malloc(numBytes);
for (int i = 0; i < elemCount; i++){
h_input[i] = float(i);
}
float* d_input,* d_output;
cudaMalloc((void**)&d_input, numBytes);
cudaMalloc((void**)&d_output, numBytes);
cudaMemcpy(d_input, h_input, numBytes, cudaMemcpyHostToDevice);
for (int i = 0; i < warmup; i++){
call_v2<BLKDIM_x, BLKDIM_y>(d_output, d_input, M, N);
}
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start);
for (int i = 0; i < repeat_time; i++){
call_v2<BLKDIM_x, BLKDIM_y>(d_output, d_input, M, N);
}
cudaEventRecord(end);
cudaEventSynchronize(end);
float v2_time = 0;
cudaEventElapsedTime(&v2_time, start, end);
std::cout << "blockdim:(" << BLKDIM_x << "," << BLKDIM_y << ")" << std::endl;
std::cout << "v2 time:" << v2_time << "ms" << std::endl;
std::cout << "---------------------" << std::endl;
cudaDeviceSynchronize();
cudaMemcpy(h_output, d_output, numBytes, cudaMemcpyDeviceToHost);
cudaEventDestroy(start);
cudaEventDestroy(end);
cudaFree(d_output);
cudaFree(d_input);
free(h_input);
return h_output;
}
bool isMatch(float* a, float* b, int elemCount){
for (int i = 0; i < elemCount; i++){
if (fabsf(a[i] - b[i]) > 1e-5) return false;
}
return true;
}
int main(){
int N = 2048, M = 512;
int numBytes = N * M * sizeof(float);
float* cpu_output = (float*)malloc(numBytes);
float* v2_output1 = (float*)malloc(numBytes);
float* v2_output2 = (float*)malloc(numBytes);
cpu_output = transpose_cpu(cpu_output, N, M);
v2_output1 = v2_time<32, 8>(M, N, 10, 10);
v2_output2 = v2_time<16, 16>(M, N, 10, 10);
if (isMatch(cpu_output, v2_output1, N * M)){
std::cout << "Results1 Match!" << std::endl;
}
else{
std::cout << "Results not Match!" << std::endl;
}
if (isMatch(cpu_output, v2_output2, N * M)){
std::cout << "Results2 Match!" << std::endl;
}
else{
std::cout << "Results not Match!" << std::endl;
}
}
运行结果:
blockdim:(32,8)
v2 time:0.345088ms
---------------------
blockdim:(16,16)
v2 time:0.111616ms
---------------------
Results1 Match!
Results2 Match!
在nsight compute中:
(32,8):
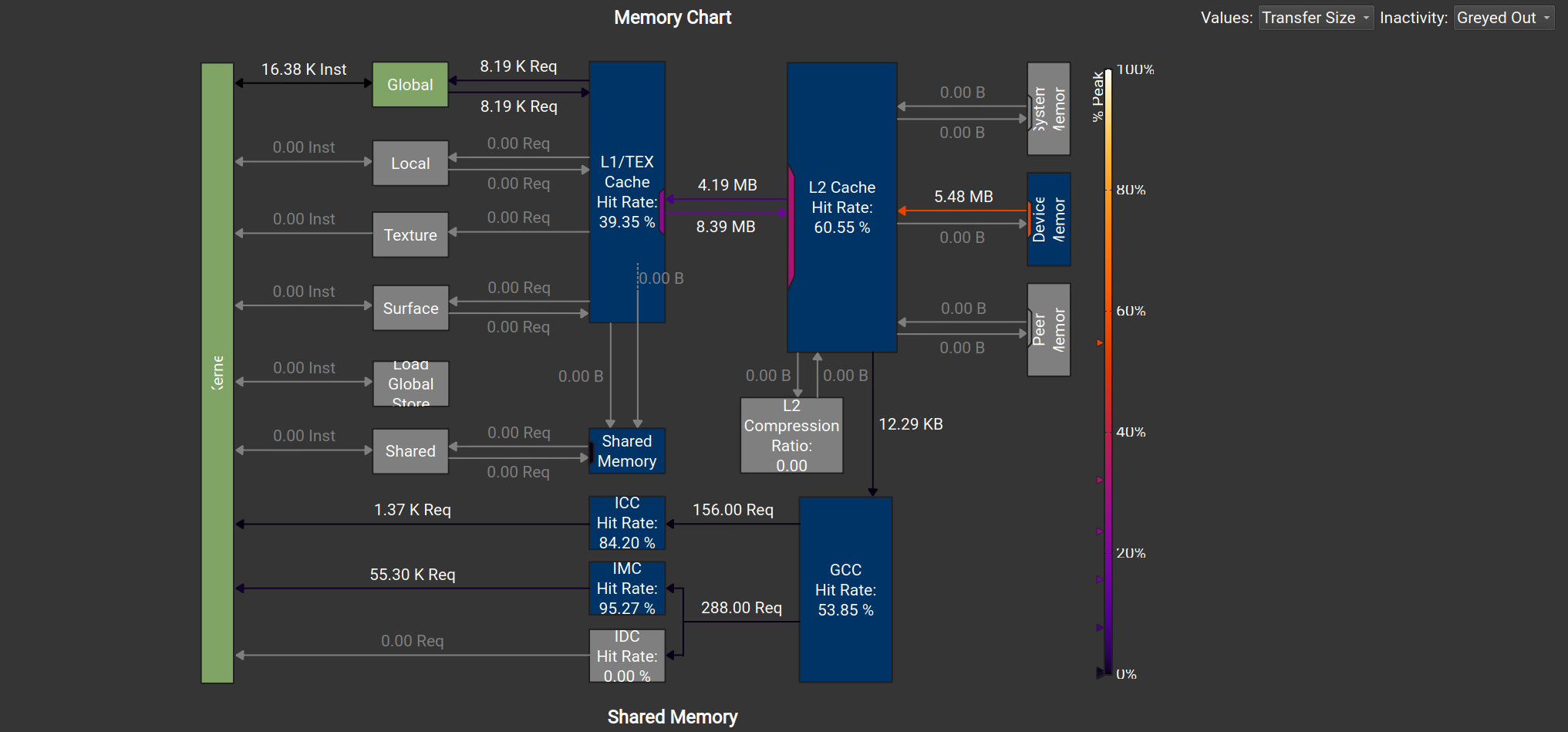
(16,16):
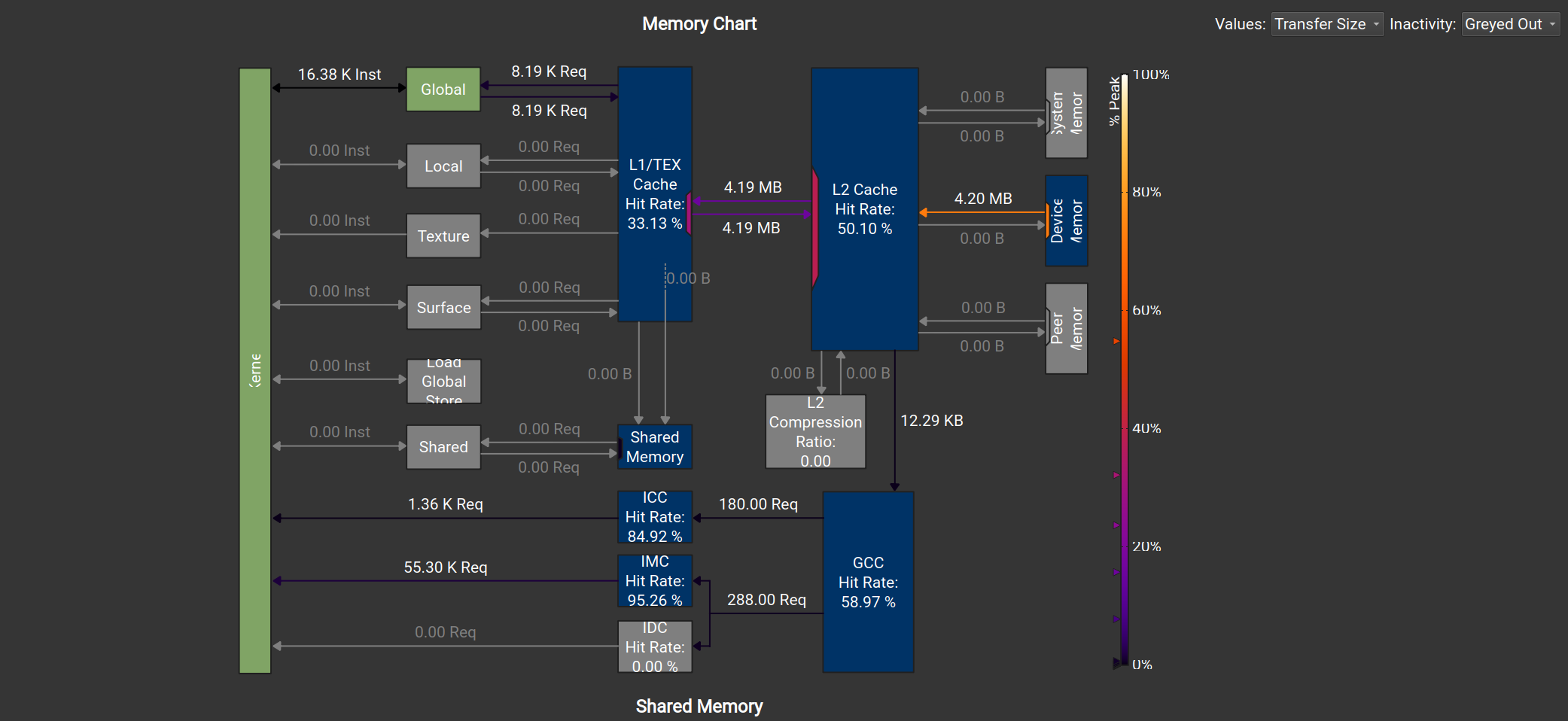
L1 cache -> L2 cache中的数据传输量大约是前者的一半
Bank Conflict(存储体冲突)
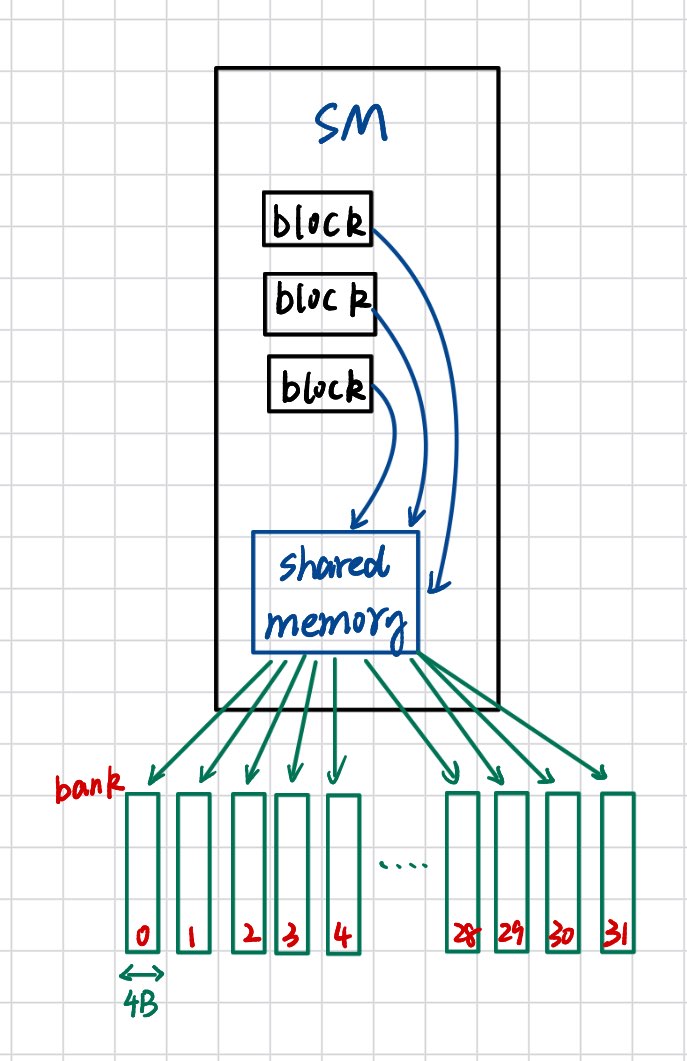
我们先来弄清楚什么是bank(存储体)?
我们先来讲解什么是SM。SM(Streaming Multiprocessor,流式多处理器) 就是 GPU 的计算核心单元,它负责执行线程、进行算术逻辑运算、访存、调度等等。我们可以把它理解为:
CPU里有多个核心(core),GPU里有多个SM
| 类比对象 | GPU | CPU |
|---|---|---|
| 运算核心 | SM(Streaming Multiprocessor) | Core(核心) |
| 调度单位 | Warp(32线程) | 指令线程 |
| 局部缓存 | Shared Memory(共享内存) | L1 Cache |
| 全局内存 | Global Memory(显存) | DRAM / 内存 |
SM的工作原理:
-
GPU 启动 kernel 后,会把线程分成很多个 block;
-
每个 block 会被分配到一个 SM 上运行;
-
SM 再把 block 里的线程拆成多个 warp(32个线程);
-
Warp Scheduler(调度器)会轮流调度这些 warp 去执行指令;
-
每个 warp 的指令会被并行送到多个 CUDA Core 中执行;
-
如果有共享数据,就放在这个 SM 的 shared memory 里。
每个 SM 上都有一块共享显存,SM 上的每个 block 共享这一块共享显存池(shared memory pool),但是每个block在这块共享显存中都有自己独立的一部分区域。一个 SM 上的共享显存又被分成32个 bank,这样一个warp中的每个线程正好对应一个bank。
什么是bank conflict呢?我们假设每个字是 4B:
那么:
-
地址0-3位于bank0
- 地址4-7位于bank1
- 地址8-11位于bank2
- …
- 地址124-127位于bank31
- 地址128-131又回到了bank0
于是,地址与存储体之间形成了一种周期性映射关系。
如果不同的线程访问同一个bank的不同数据,那么就会导致bank conflict。
例如,线程0访问地址0(bank0的第一个数据),线程1访问地址128(bank0的第二个数据),那么二者就会产生bank conflict。
需要注意的是,同一地址的并发访问不构成bank conflict。比如多个线程同时访问地址0,那么它们访问的都是bank0中的同一个数据,硬件可以广播该数据给多个线程。
共享显存优化中的bank conflict例子
我们来看一个利用共享显存优化的例子:
// 共享显存优化
template <const int BLKDIM_X, const int BLKDIM_Y>
__global__ void transpose_v2(float* output, float* input, int M, int N) {
__shared__ float tile[BLKDIM_Y][BLKDIM_X];
const int id_x = threadIdx.x + blockIdx.x * blockDim.x;
const int id_y = threadIdx.y + blockIdx.y * blockDim.y;
if (id_x < N && id_y < M)
{
tile[threadIdx.y][threadIdx.x] = input[id_y * N + id_x];
}
__syncthreads();
const int block_x_out = blockIdx.y * BLKDIM_Y;
const int block_y_out = blockIdx.x * BLKDIM_X;
const int trans_x = block_x_out + threadIdx.x;
const int trans_y = block_y_out + threadIdx.y;
if (trans_x < M && trans_y < N)
{
output[trans_y * M + trans_x] = tile[threadIdx.x][threadIdx.y];
}
}
其中,BLKDIM_X,BLKDIM_Y都配置为32。
我们来分析bank conflict情况:
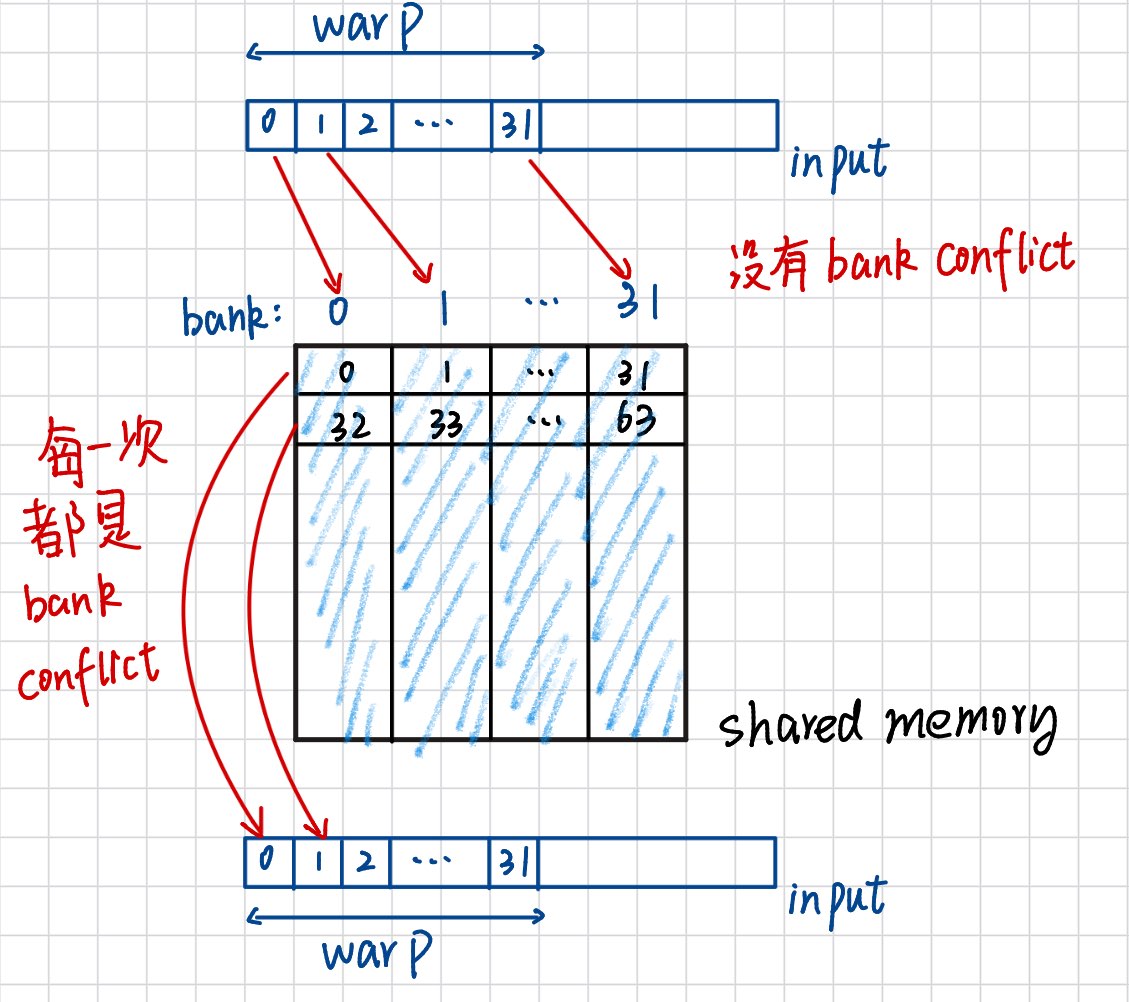
由上图可以看出,在input -> tile 阶段,warp中的每个线程都访问的是不同的bank,所以没有bank conflict。
在tile -> output阶段,相邻线程访问的地址都相差BLKDIM_X * sizeof(float)字节,warp中的所有线程都访问的是同一个warp,性能直接下降了32倍!
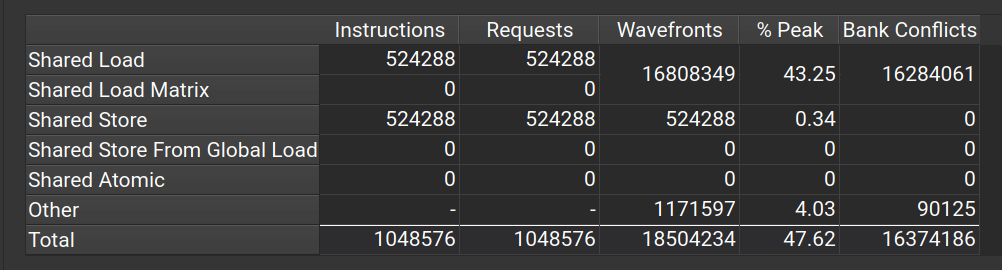
在nsight compute中可以看到,bank conflict主要集中在shared load中,也就是 tile -> output。而shared store的bank conflict为0,也就是input -> tile。这与我们刚才的分析相吻合。
那如何避免bank conflict呢?从以上的分析我们知道,问题就出在相邻线程访问的地址都相差BLKDIM_X * sizeof(float)字节上,那我们只要把BLKDIM_X改变个值(比如+1)不就好了?
template <const int BLKDIM_X, const int BLKDIM_Y>
__global__ void transpose_v2(float* output, float* input, int M, int N) {
__shared__ float tile[BLKDIM_Y][BLKDIM_X + 1];
const int id_x = threadIdx.x + blockIdx.x * blockDim.x;
const int id_y = threadIdx.y + blockIdx.y * blockDim.y;
if (id_x < N && id_y < M)
{
tile[threadIdx.y][threadIdx.x] = input[id_y * N + id_x];
}
__syncthreads();
const int block_x_out = blockIdx.y * BLKDIM_Y;
const int block_y_out = blockIdx.x * BLKDIM_X;
const int trans_x = block_x_out + threadIdx.x;
const int trans_y = block_y_out + threadIdx.y;
if (trans_x < M && trans_y < N)
{
output[trans_y * M + trans_x] = tile[threadIdx.x][threadIdx.y];
}
}
可以看到,虽然没有完全避免bank conflict,但是相比之前性能已经提升了很多了。
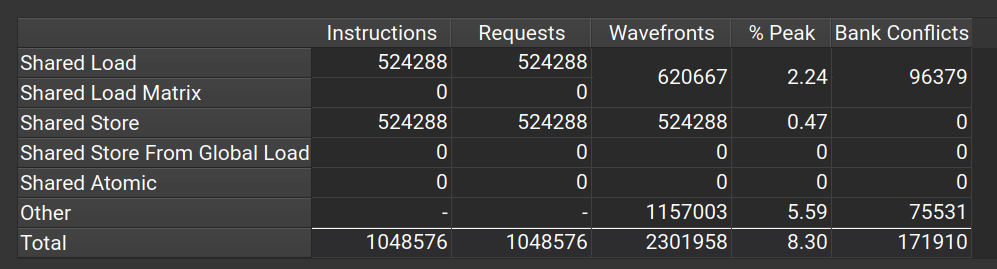
在nsight compute中我们可以看到,shared load阶段的bank conflict已经大大减少了。
完整代码:
#include <iostream>
#include "cuda_runtime.h"
float* transpose_cpu(float* output, int nx, int ny){
float* input = (float*)malloc(sizeof(float) * nx * ny);
for (int i = 0; i < nx * ny; i++){
input[i] = float(i);
}
for (int i = 0; i < ny; i++){
for (int j = 0; j < nx; j++){
// output[j][i] = input[i][j];
output[j * ny + i] = input[i * nx + j];
}
}
return output;
}
template <const int BLKDIM_X, const int BLKDIM_Y, const int PAD>
__global__ void transpose_v2(float* output, float* input, int M, int N) {
__shared__ float tile[BLKDIM_Y][BLKDIM_X + PAD];
const int id_x = threadIdx.x + blockIdx.x * blockDim.x;
const int id_y = threadIdx.y + blockIdx.y * blockDim.y;
if (id_x < N && id_y < M)
{
tile[threadIdx.y][threadIdx.x] = input[id_y * N + id_x];
}
__syncthreads();
const int block_x_out = blockIdx.y * BLKDIM_Y;
const int block_y_out = blockIdx.x * BLKDIM_X;
const int trans_x = block_x_out + threadIdx.x;
const int trans_y = block_y_out + threadIdx.y;
if (trans_x < M && trans_y < N)
{
output[trans_y * M + trans_x] = tile[threadIdx.x][threadIdx.y];
}
}
template <const int BLKDIM_X, const int BLKDIM_Y, const int PAD>
void call_v2(float* d_output, float* d_input, int M, int N){
dim3 blockSize(BLKDIM_X, BLKDIM_Y);
dim3 gridSize((M + blockSize.x - 1) / blockSize.x, (N + blockSize.y) / blockSize.y);
transpose_v2<BLKDIM_X, BLKDIM_Y, PAD><<<gridSize, blockSize>>>(d_output, d_input, M, N);
}
template <const int BLKDIM_X, const int BLKDIM_Y, const int PAD>
float* v2_time(int M, int N, int warmup, int repeat_time){
int elemCount = M * N;
int numBytes = elemCount * sizeof(float);
float* h_input,* h_output;
h_input = (float*)malloc(numBytes);
h_output = (float*)malloc(numBytes);
for (int i = 0; i < elemCount; i++){
h_input[i] = float(i);
}
float* d_input,* d_output;
cudaMalloc((void**)&d_input, numBytes);
cudaMalloc((void**)&d_output, numBytes);
cudaMemcpy(d_input, h_input, numBytes, cudaMemcpyHostToDevice);
for (int i = 0; i < warmup; i++){
call_v2<BLKDIM_X, BLKDIM_Y, PAD>(d_output, d_input, M, N);
}
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start);
for (int i = 0; i < repeat_time; i++){
call_v2<BLKDIM_X, BLKDIM_Y, PAD>(d_output, d_input, M, N);
}
cudaEventRecord(end);
cudaEventSynchronize(end);
float v2_time = 0;
cudaEventElapsedTime(&v2_time, start, end);
std::cout << "v2 time:" << v2_time << "ms" << std::endl;
cudaDeviceSynchronize();
cudaMemcpy(h_output, d_output, numBytes, cudaMemcpyDeviceToHost);
cudaEventDestroy(start);
cudaEventDestroy(end);
cudaFree(d_output);
cudaFree(d_input);
free(h_input);
return h_output;
}
bool isMatch(float* a, float* b, int elemCount){
for (int i = 0; i < elemCount; i++){
if (fabsf(a[i] - b[i]) > 1e-5) return false;
}
return true;
}
int main(){
int M = 512, N = 2048;
int numBytes = M * N * sizeof(float);
float* cpu_output = (float*)malloc(numBytes);
float* v1_output = (float*)malloc(numBytes);
float* v2_output = (float*)malloc(numBytes);
cpu_output = transpose_cpu(cpu_output, M, N);
std::cout << "PAD:" << 0 << std::endl;
v2_output = v2_time<32, 32, 0>(M, N, 10, 10);
std::cout << "PAD:" << 1 << std::endl;
v2_output = v2_time<32, 32, 1>(M, N, 10, 10);
if (isMatch(cpu_output, v2_output, M * N)){
std::cout << "Results Match!" << std::endl;
}
else{
std::cout << "Results not Match!" << std::endl;
}
}
运行结果:
PAD:0
v2 time:0.466944ms
PAD:1
v2 time:0.248832ms
Results Match!