Effective Modern C++ Note
item1:理解模板类型推导
什么是函数模板?
问题场景:假设我们要写一个函数,用来比较两个数并返回较大的那个。
// 比较两个 int
int max_int(int a, int b) {
return (a > b) ? a : b;
}
// 比较两个 double
double max_double(double a, double b) {
return (a > b) ? a : b;
}
// 比较两个 char
char max_char(char a, char b) {
return (a > b) ? a : b;
}
int main() {
std::cout << max_int(10, 20) << std::endl; // 输出 20
std::cout << max_double(3.14, 2.71) << std::endl; // 输出 3.14
std::cout << max_char('A', 'Z') << std::endl; // 输出 Z
}
这三个函数的逻辑完全一样,唯一的区别就是参数和返回值的类型不同。这导致了大量的代码冗余。如果我们还想比较 float、long 等类型,就需要写更多重复的函数。
解决方案:使用函数模板
#include <iostream>
// 这就是函数模板
template <typename T> // 可以用class关键字代替typename
T generic_max(T a, T b) {
return (a > b) ? a : b;
}
int main() {
// 编译器看到这里传入了两个 int
// 于是自动用 int 替换 T,生成一个 int generic_max(int, int) 函数
std::cout << generic_max(10, 20) << std::endl;
// 编译器看到这里传入了两个 double
// 于是自动用 double 替换 T,生成一个 double generic_max(double, double) 函数
std::cout << generic_max(3.14, 2.71) << std::endl;
// 编译器看到这里传入了两个 char
// 于是自动用 char 替换 T,生成一个 char generic_max(char, char) 函数
std::cout << generic_max('A', 'Z') << std::endl;
// 我们甚至可以用它来比较 std::string
std::string s1 = "hello";
std::string s2 = "world";
std::cout << generic_max(s1, s2) << std::endl; // 输出 world
}
模板类型的推导
ParamType既不是指针也不是引用
当ParamType既不是指针也不是引用时,我们通过传值(pass-by-value)的方式处理
template<typename T>
void f(T param); //以传值的方式处理param
当一个函数模板的参数是按值传递时(例如 T x),编译器在推导 T 的类型时会遵循以下规则:
参数的
const、volatile和引用&属性都会被忽略(或称“剥离”)。
为什么呢?因为函数无论如何都会得到一个全新的、独立的副本。原始变量是不是 const,或者是不是一个引用,对于这个新创建的副本来说都无所谓。副本本身就是一个普通的、可修改的局部变量。param是一个完全独立于cx和rx的对象——是cx或rx的一个拷贝
例子:
template<typename T>
T increse(T x){
return ++x;
}
int main() {
int x = 1;
const int cx = x;
const int& rx = x;
std::cout << "increse(x):" << increse(x) << std::endl;
std::cout << "x:" << x << std::endl;
std::cout << "increse(cx): "<< increse(cx) << std::endl;
std::cout << "cx:" << cx << std::endl;
std::cout << "increse(rx):" << increse(rx) << std::endl;
std::cout << "rx:" << rx << std::endl;
}
打印结果:
increse(x):2
x:1
increse(cx): 2
cx:1
increse(rx):2
rx:1
ParamType是指针或者非通用引用
非通用引用,就是T&
template<typename T>
T increse(T& x){
return ++x;
}
当我们把参数从值传递 (T x) 改为引用传递 (T& x) 时,类型推导的规则也发生了根本性的变化:
对于引用参数,
const属性会被保留在类型推导中。
为什么呢?这是为了保证 C++ 的“const 正确性” (const-correctness)。语言不允许你创建一个非 const 的引用去指向一个 const 的变量,因为那样会给你一个修改常量的“后门”。所以,如果传入的实参是 const 的,T 就必须被推导为 const 类型,以形成一个合法的 const 引用。
逐行分析:
调用 1: increse(x)
- 参数:
x的类型是int。 - 类型推导: 编译器需要将
T&与int匹配。为了让T&成为int&,T被直接推导为int。 - 模板实例化: 编译器生成
T = int的版本:
int increse(int& x) { // x 是 main 函数中 x 的引用
return ++x; // main 函数中的 x 被修改为 2,然后返回 2
}
- 行为:
main函数中的x的值被永久地从1修改为2。- 输出
2。
- 结果: 编译成功,并有副作用。
调用 2: increse(cx)
- 参数:
cx的类型是const int。 - 类型推导: 编译器需要将
T&与const int匹配。- 根据新规则,
const属性必须被保留。 - 因此,
T被推导为const int。这样T&就变成了const int&,这是一个合法的引用,可以绑定到const int类型的cx上。
- 根据新规则,
- 模板实例化: 编译器尝试生成
T = const int的版本
// 这是编译器尝试生成的函数
const int increse(const int& x) {
return ++x; // <-- 错误在这里!
}
- 问题: 在这个生成的函数体内,参数
x的类型是const int&。我们不能对一个常量(或常量引用)使用++自增操作符,因为这个操作符会试图修改它的值。 - 结果: 编译失败! 编译器会报错,错误信息通常类似于:“
对只读参数 'x' 进行自增操作” 或 “increment of read-only parameter 'x'”。
调用 3: increse(rx)
- 参数:
rx的类型是const int&。 - 类型推导: 和上一个例子完全一样。
rx是一个对const int的引用,所以传递给函数的实参本质上就是那个const的值。为了匹配T&,T必须被推导为const int。 - 模板实例化: 编译器同样尝试生成
const int版本的函数,也同样会在return ++x;这一行遇到错误。 - 结果: 编译失败! 原因和调用
increse(cx)完全相同
在第三个例子中,注意即使rx的类型是一个引用,T也会被推导为一个非引用 ,这是因为rx的引用性(reference-ness)在类型推导中会被忽略。
ParamType是通用引用(转发引用)
当 T&& 出现在一个需要进行模板类型推导的上下文时,它就变成了“通用引用”。
- 定义:它是一种特殊的引用,既可以绑定到左值,也可以绑定到右值。它会根据传入参数的值类别(左值或右值)来改变自己的行为。
- 语法:
T&&,其中T是一个正在被推导的函数模板参数。 - 主要用途:实现完美转发 (Perfect Forwarding),即在函数调用链中保持参数原始的值类别(左值还是右值)。
例子:
template<typename T>
void forwarder(T&& arg) { // 这里的 arg 是一个通用引用(转发引用)
// ... 在这里我们可以用 std::forward<T>(arg) 来完美转发 ...
std::cout << "参数被接收..." << std::endl;
}
int main() {
int x = 10;
const int cx = 20;
forwarder(x); // 正确!传入一个左值 int
forwarder(cx); // 正确!传入一个 const 左值 int
forwarder(42); // 正确!传入一个右值 int
forwarder(std::move(x)); // 正确!传入一个右值 int
}
-
当传入一个左值时 (例如
int x):模板参数
T会被推导为int&(一个左值引用类型)函数参数的类型就变成了
T&&->int& &&根据引用折叠规则,
& + &&折叠成&所以,最终的函数参数类型是
int&,一个普通的左值引用 -
当传入一个右值时 (例如
42):模板参数
T会被推导为int(一个非引用类型)函数参数的类型就变成了
T&&->int&&这本身就是一个右值引用,无需折叠
最终的函数参数类型是
int&&,一个右值引用
通用转发有什么用?
看下面这个例子:
#include <vector>
#include <string>
#include <iostream>
struct Person {
std::string name;
int age;
Person(const std::string& n, int a) : name(n), age(a) {
std::cout << "构造函数 (const std::string&, int) 被调用" << std::endl;
}
Person(const Person& other) : name(other.name), age(other.age) {
std::cout << "拷贝构造函数被调用" << std::endl;
}
Person(Person&& other) noexcept : name(std::move(other.name)), age(other.age) {
std::cout << "移动构造函数被调用" << std::endl;
}
};
int main() {
std::vector<Person> people;
// 关键!提前预留足够的空间,避免重分配
people.reserve(2);
std::cout << "--- 使用 push_back ---" << std::endl;
// 过程:
// 1. 在 main 函数栈上创建一个临时的 Person 对象 ("Alice", 25)。
// 2. push_back 接收这个临时对象。
// 3. 在 vector 内部的内存空间,调用移动构造函数,将临时对象的内容移动过去。
people.push_back(Person("Alice", 25));
// 输出:
// 构造函数 (const std::string&, int) 被调用
// 移动构造函数被调用
std::cout << "\n--- 使用 emplace_back ---" << std::endl;
// 过程:
// 1. emplace_back 接收构造函数所需的参数 ("Bob", 30)。
// 2. 它在vector 内部预留好的内存空间里,直接调用 Person 的构造函数,原地构造对象。
people.emplace_back("Bob", 30);
// 输出:
// 构造函数 (const std::string&, int) 被调用
}
运行结果:
--- 使用 push_back ---
构造函数 (const std::string&, int) 被调用
移动构造函数被调用
--- 使用 emplace_back ---
构造函数 (const std::string&, int) 被调用
emplace_back 是如何做到的?
它的函数签名大致如下:
template<typename... Args>
void emplace_back(Args&&... args) {
// ... 在 vector 内部申请内存 ...
// 使用完美转发,将接收到的参数原封不动地传递给 Person 的构造函数
new (memory_location) Person(std::forward<Args>(args)...);
}
Args&&... args就是一个通用引用的参数包。- 如果调用
emplace_back("Bob", 30),"Bob"是右值,30也是右值,std::forward会将它们作为右值转发给Person的构造函数。 - 如果调用
std::string name = "Charlie"; emplace_back(name, 40);,name是左值,std::forward会保证它作为左值被转发,从而调用Person(const std::string&, int)构造函数。
数组实参
template<typename T>
void f(T arr){
std::cout << "size of arr is:" << sizeof(arr) << std::endl;
}
int main() {
int arr[3] = {1, 2, 3};
f(arr);
}
//打印结果:8
在以上例子中,T 被推导为 int\* (一个指向 int 的指针)。
在 C++ 中,当一个数组名在大多数表达式中使用时(有少数例外),它会自动 “退化” 或 “转换” 为一个指向其首元素的指针。
f(arr) 这个函数调用就是一个典型的会发生数组退化的表达式。当你把数组 arr (其类型是 int[3]) 作为参数传递给函数 f 时,它实际上被转换成了一个指向 arr[0] 的指针,这个指针的类型是 int*。
模板函数 f 的参数是 T,这是一个按值传递 (pass-by-value) 的参数。类型推导机制会查看你传递给函数的实际值的类型。由于 arr 已经退化成了 int* 类型的指针值,所以模板系统将 T 推导为 int*。
怎么防止数组类型在模板推导时退化成指针呢?使用引用!
简单来说,引用可以防止数组退化,是因为引用直接绑定到对象本身,而不需要获取该对象的“值”。数组退化恰恰发生在“获取数组的值”这个过程中。
f的形参(该数组的引用)的类型则为
int (&)[3]
让我们用一个形象的比喻来解释,然后深入到编译器的行为。
假设你有一个实体文件夹,里面有三份文件,文件夹上贴着标签“项目 A” (int arr[3])。
- 场景一:按值传递(会退化)
- 我让你把“项目 A”文件夹里的内容给我。
- 你不会把整个文件夹给我。按照惯例,你会告诉我:“内容在一楼第一个抽屉里”。你给我的是一个地址/指针 (
int*)。 - 我拿到了这个地址,但我不知道这个“项目”到底有多大(是3份文件还是10份?),我只知道从哪里开始找。
- 这就是数组退化:为了“传递”这个数组,你把它简化成了一个指向其开头的指针。
- 场景二:按引用传递(不退化)
- 我说:“让我直接使用一下你的‘项目 A’文件夹”。
- 你没有给我地址,也没有给我复印件。你只是授权我直接操作你桌上那个原封不动的文件夹。
- 我操作的就是那个原始的、完整的、带有“3份文件”这个全部信息的文件夹 (
int[3])。我给它起了个别名来用,但它本质没变。 - 这就是引用:它创建了一个别名,直接绑定到原始对象上,对象的类型和所有属性(包括大小)都被完整保留。
template<typename T>
void f(T& arr){
std::cout << "size of arr is:" << sizeof(arr) << std::endl;
}
int main() {
int arr[3] = {1, 2, 3};
f(arr);
}
//打印结果:12
函数实参
在C++中不只是数组会退化为指针,函数类型也会退化为一个函数指针,我们对于数组类型推导的全部讨论都可以应用到函数类型推导和退化为函数指针上来。
#include <iostream>
#include <typeinfo>
// 一个简单的函数
void greeting() {
std::cout << "Hello!" << std::endl;
}
// 案例 1: 按值传递 (会发生退化)
template<typename T>
void f_by_value(T func) {
std::cout << "f_by_value: T is deduced as " << typeid(T).name() << std::endl;
func(); // 可以像普通函数一样调用
}
// 案例 2: 按引用传递 (不发生退化)
template<typename T>
void f_by_reference(T& func) {
std::cout << "f_by_reference: T is deduced as " << typeid(T).name() << std::endl;
func();
}
int main() {
// PFvvE 是 void(*)() 的 mangled name,即函数指针
// FvvE 是 void() 的 mangled name,即函数类型
// (具体名字可能因编译器而异)
std::cout << "--- 传递函数名 greeting ---" << std::endl;
f_by_value(greeting); // (1)
f_by_reference(greeting); // (2)
std::cout << "\n--- 传递 &greeting (显式取地址) ---" << std::endl;
f_by_value(&greeting); // (3)
}
/*
打印结果:
--- 传递函数名 greeting ---
f_by_value: T is deduced as PFvvE
Hello!
f_by_reference: T is deduced as FvvE
Hello!
--- 传递 &greeting (显式取地址) ---
f_by_value: T is deduced as PFvvE
Hello!
*/
f_by_value(greeting)- 发生了什么: 和数组一样,为了将
greeting按值传递,编译器需要获取它的“值”。一个函数本身是代码段,不能被拷贝。它的“值”就是它在内存中的地址。 - 退化:
greeting(类型为void()) 自动退化成一个指向它的指针 (类型为void(*)())。 - 类型推导: 模板看到传递过来的是一个
void(*)()类型的指针,所以T被推导为void(*)()。 - 输出:
T is deduced as ...(表示一个函数指针类型void(*)())
- 发生了什么: 和数组一样,为了将
f_by_reference(greeting)- 发生了什么: 同样,引用直接绑定到对象上。它不需要获取
greeting的“值”。 - 不退化: 引用直接绑定到
greeting这个函数实体本身。 - 类型推导: 为了让
T&成功绑定到一个类型为void()的函数上,模板必须将T推导为函数类型本身,即void()。参数的最终类型是void(&)()(对函数的引用)。 - 输出:
T is deduced as ...(表示一个函数类型void())
- 发生了什么: 同样,引用直接绑定到对象上。它不需要获取
f_by_value(&greeting)- 发生了什么: 这里我们使用
&运算符显式地获取了函数的地址,结果是一个void(*)()类型的指针。 - 退化: 其实退化规则在这里也适用了,但因为我们已经显式取了地址,所以结果是完全一样的。
f_by_value(greeting)和f_by_value(&greeting)最终传递给函数的都是同一个指针值。 - 类型推导:
T毫无疑问被推导为void(*)()。
- 发生了什么: 这里我们使用
item2:理解auto类型推导
在Item1中,模板类型推导使用下面这个函数模板
template<typename T>
void f(ParmaType param);
和这个调用来解释:
f(expr); //使用一些表达式调用f
在f的调用中,编译器使用expr推导T和ParamType的类型。
当一个变量使用auto进行声明时,auto扮演了模板中T的角色,变量的类型说明符扮演了ParamType的角色。
类型说明符既不是指针也不是引用
这是最简单、最常见的情况,auto 自己就是一个独立的类型说明符。
推导规则:
- 忽略初始化表达式的引用(
&)属性。 - 忽略初始化表达式的顶层
const和volatile属性。 - 最终推导出的类型是一个全新的、独立的值类型。
#include <iostream>
int main() {
int x = 27; // x 是 int
const int cx = x; // cx 是 const int
const int& rx = x; // rx 是 const int&,是 x 的一个别名
// --- 开始推导 ---
auto a = x; // x 是 int。a 的类型被推导为 int。
// a 是 x 的一个全新副本。
auto b = cx; // cx 是 const int。规则2生效,顶层 const 被忽略。
// b 的类型被推导为 int。b 也是一个副本。
auto c = rx; // rx 是 const int&。规则1和2同时生效,引用和顶层 const 都被忽略。
// c 的类型被推导为 int。c 仍然是一个副本。
a = 100; // 修改 a 不会影响 x
b = 200; // 修改 b 不会影响 cx 或 x
c = 300; // 修改 c 不会影响 rx 或 x
std::cout << "x = " << x << std::endl; // 输出: x = 27
std::cout << "a = " << a << std::endl; // 输出: a = 100
std::cout << "b = " << b << std::endl; // 输出: b = 200
std::cout << "c = " << c << std::endl; // 输出: c = 300
// 如果想保留 const,需要自己加上
const auto d = cx; // d 的类型被推导为 const int
// d = 400; // 错误:不能给 const 变量赋值
}
在这种情况下,auto 总是产生一个非引用、非 const 的新副本(除非你自己加上 const)。
类型说明符是一个指针或非通用引用
这种情况包括 auto&, const auto&, auto* 等。
推导规则:
auto会首先“匹配”初始化表达式的类型。- 引用和
const属性不再被忽略,它们会参与到类型匹配中。 - 编译器会根据
auto旁边的修饰符(&,*,const)来最终确定类型。
#include <iostream>
int main() {
int x = 27;
const int cx = x;
// --- 推导 auto& (左值引用) ---
auto& a = x; // x 是 int。auto 被推导为 int,所以 a 的类型是 int&。
// a 是 x 的别名。
auto& b = cx; // cx 是 const int。auto 被推导为 const int,所以 b 的类型是 const int&。
// b 是 cx 的别名。
// auto& c = 27; // 错误:不能将一个非常量左值引用绑定到右值 27。
a = 50; // 修改 a 就是修改 x
// b = 60; // 错误:b 是一个常量引用,不能通过它修改值。
std::cout << "x after changing a: " << x << std::endl; // 输出: 50
// --- 推导 const auto& (常量左值引用) ---
const auto& d = x; // x 是 int。auto 推导为 int,d 的类型是 const int&。
const auto& e = cx; // cx 是 const int。auto 推导为 int,e 的类型是 const int&。
const auto& f = 27; // 27 是右值。auto 推导为 int,f 的类型是 const int&。
// 常量左值引用可以绑定到右值。
// --- 推导 auto* (指针) ---
int* px = &x;
const int* cpx = &x;
auto* g = px; // px 是 int*。auto 推导为 int,g 的类型是 int*。
auto* h = cpx; // cpx 是 const int*。auto 推导为 const int,h 的类型是 const int*。
// 注意:这里的 const 是底层的(指向的内容是 const),它被保留了。
}
在这种情况下,auto 扮演的是一个“类型匹配者”的角色。&、* 和 const 都会被保留和尊重,推导结果更加“字面化”。
类型说明符是一个通用引用
这种情况特指 auto&&。它遵循特殊的引用折叠规则。
推导规则:
- 如果初始化表达式是左值 (Lvalue),
auto会被推导为T&,最终类型为T& &&,折叠为T&(左值引用)。 - 如果初始化表达式是右值 (Rvalue),
auto会被推导为T,最终类型为T&&(右值引用)。
#include <iostream>
int main() {
int x = 27;
const int cx = x;
// --- 推导 auto&& ---
// 规则1:用左值初始化
auto&& a = x; // x 是一个 int 类型的左值。
// auto 被推导为 int&。
// a 的类型是 int& &&,折叠后为 int& (左值引用)。
// a 绑定到 x。
auto&& b = cx; // cx 是一个 const int 类型的左值。
// auto 被推导为 const int&。
// b 的类型是 const int& &&,折叠后为 const int& (常量左值引用)。
// b 绑定到 cx。
a = 99; // 可以修改,因为 a 是 int&
// b = 100; // 错误,因为 b 是 const int&
std::cout << "x after changing a: " << x << std::endl; // 输出: 99
// 规则2:用右值初始化
auto&& c = 27; // 27 是一个 int 类型的右值。
// auto 被推导为 int。
// c 的类型是 int&& (右值引用)。
// c 绑定到临时量 27。
c = 101; // 可以修改右值引用的值
std::cout << "c = " << c << std::endl; // 输出: 101
}
和顶层const,底层const结合:
#include <iostream>
int main() {
int val = 10;
const int* const x = &val;
auto a = x; // 类型被推导为 const int* !
/*
注意第一点就说过的:
当执行拷贝操作时:
1. 顶层 const 可以忽略
2. 底层 const 必须保持一致
*/
std::cout << *a << std::endl; // 合法
a++; // 合法!因为a的类型是const int*, 表示a指向的内容是const, 而a本身(地址)不是const
//(*a)++; // 不合法!a指向的内容是const
}
auto类型推导和模板类型推导之间的区别
auto 类型推导假定花括号初始化代表 std::initializer_list
auto x = {1, 2, 3}; // x 的类型是 std::initializer_list<int>
auto y = {10}; // y 的类型是 std::initializer_list<int>
// auto z = {1, 2.0}; // 编译错误:初始化列表中的元素类型必须一致
#include <iostream>
template <typename T>
void func(T param) {
// ...
}
template <typename T>
void func_ref(T& param) {
// ...
}
template <typename T>
void func_fwd(T&& param) {
// ...
}
int main() {
// func({1, 2, 3}); // 编译错误!T 无法从 {1, 2, 3} 推导出来。
// func_ref({1, 2, 3}); // 编译错误!T& 无法绑定到 {1, 2, 3},也无法推导 T。
// func_fwd({1, 2, 3}); // 编译错误!T&& 也无法从 {1, 2, 3} 推导出来。
}
为什么会这样?
对于模板函数,{1, 2, 3} 是一个初始化列表,但它本身没有具体类型。它不是一个 std::initializer_list 对象,而是一个可以用来构造 std::initializer_list 对象或其他支持列表初始化的对象的语法结构。编译器无法仅凭 T 来确定 T 应该如何处理这个花括号列表。
但是,你可以显式地指定 std::initializer_list 类型:
template <typename T>
void process_list(std::initializer_list<T> list_param) {
for (const auto& item : list_param) {
std::cout << item << " ";
}
std::cout << std::endl;
}
process_list({1, 2, 3}); // 合法!T 被推导为 int。
// 因为函数参数类型明确要求 std::initializer_list<T>
item3:理解decltype
decltype 是 C++11 引入的一个关键字,用于在编译时推断并返回表达式的准确类型。与 auto 关键字不同,decltype 推断的类型会保留表达式的引用性(lvalue/rvalue)和 const/volatile 限定符,提供更精确的类型信息。
decltype 的基本用法
decltype(expression)
其中 expression 是一个有效的 C++ 表达式。decltype 会推断这个表达式的类型,但 不会实际评估 这个表达式。
int x = 0;
decltype(x) y = x; // y 的类型是 int
const int& rx = x;
decltype(rx) ry = rx; // ry 的类型是 const int&
const int cx = 0;
decltype(cx) cy = cx; // cy 的类型是 const int
int* ptr = &x;
decltype(ptr) p2 = ptr; // p2 的类型是 int*
int arr[5];
decltype(arr) arr2; // arr2 的类型是 int[5]
推断表达式的类型
这是 decltype 最强大也最容易混淆的地方。当 expression 不是变量名,而是一个更复杂的表达式时,decltype 的行为取决于表达式是 左值 (lvalue) 还是 右值 (rvalue)。
- 如果表达式是一个左值 (lvalue),
decltype推断出的类型是T&(引用类型),并保留const/volatile限定符。 - 如果表达式是一个右值 (rvalue),
decltype推断出的类型是T(非引用类型),并保留const/volatile限定符
int i = 42;
// 情况 1: 变量名 (总是左值)
decltype(i) a = i; // a 的类型是 int (因为 i 是一个变量名,而不是一个表达式,decltype(i) 直接获取i的声明类型)
// 情况 2: 加括号的变量名 (强制为左值表达式)
decltype((i)) b = i; // b 的类型是 int& (因为 (i) 是一个左值表达式)
b = 100; // i 变为 100
// 情况 3: 算术表达式 (通常是右值)
decltype(i + 1) c = i + 1; // c 的类型是 int (i + 1 是一个右值表达式)
// 情况 4: 解引用操作 (通常是左值)
int* p = &i;
decltype(*p) d = *p; // d 的类型是 int& (*p 是一个左值表达式)
d = 200; // i 变为 200
// 情况 5: 函数调用
int& get_ref() { return i; }
int get_val() { return i; }
decltype(get_ref()) e = get_ref(); // e 的类型是 int& (get_ref() 返回左值引用)
decltype(get_val()) f = get_val(); // f 的类型是 int (get_val() 返回右值)
const int ci = 0;
decltype((ci)) g = ci; // g 的类型是 const int& ((ci) 是一个 const 左值表达式)
struct MyStruct { int x; };
MyStruct ms;
decltype(ms.x) h = ms.x; // h 的类型是 int (ms.x 作为变量名,直接获取类型)
decltype((ms.x)) k = ms.x; // k 的类型是 int& ((ms.x) 作为左值表达式)
在泛型编程中推断返回类型
当函数的返回类型依赖于其模板参数时,decltype 和尾随返回类型语法非常有用。
template<typename Container, typename Index>
auto f(Container& c, Index i) -> decltype(c[i]){
c[i]++;
return c[i];
}
int main() {
std::vector<float> v(10);
f(v, 1) = 10;
}
这样写是正确的!函数f()指定了返回值decltype(c[i]),类型是float&。对于 std::vector<float>,operator[] 返回的是 float& (一个对元素的引用)。因此,decltype(c[i]) 在这里会被推断为 float&。这意味着函数 f 返回的是一个 float 类型的引用。
结果将v[1]的值变为10
注意!如果这样写就是错误的!
template<typename Container, typename Index>
auto f(Container& c, Index i){
c[i]++;
return c[i];
}
int main() {
std::vector<float> v(10);
//f(v, 1) = 10; // 错误!
}
因为函数f()没有指明返回值类型,auto自动推导忽略了&,返回值类型变为float
此时f(v, 1) = 10就相当于给一个右值赋值,肯定是错误的
还有一种写法:使用decltype(auto)
template<typename Container, typename Index>
decltype(auto) f(Container& c, Index i){
c[i]++;
return c[i];
}
int main() {
std::vector<float> v(10);
f(v, 1) = 10;
}
我们可以这样解释它的意义:auto说明符表示这个类型将会被推导,decltype说明decltype的规则将会被用到这个推导过程中。
运用了decltype规则推导,则&就会被保留下来,所以返回值类型成了float &
decltype(auto)也可用于普通变量的类型推导
int x = 10;
const int cx = 11;
decltype(auto) a = cx;
auto b = cx;
//a++; // 错误!
b++; //正确!
decltype(auto) a = cx;表示使用decltype的规则推导,则const被保留,所以a的类型是const int,不能被修改
再看一个例子:
template<typename Container, typename Index>
decltype(auto) f(Container&& c, Index i){
return c[i];
}
// 把很多字符串放到一个队列里
std::deque<std::string> makeStringDeque();
int main() {
auto s = f(makeStringDeque(), 5);// 要获取第五个字符串
}
注意!这里的函数f()中的Container&& c必须使用通用引用&&!
因为函数makeStringDeque()的返回值是一个右值!
itme5:优先考虑auto而非显式类型声明
在声明变量时,尽可能使用 auto 关键字让编译器去推断类型,而不是自己手动写出完整的类型。
例如:
// 传统方式
int x = 0;
std::vector<int>::iterator it = myVec.begin();
// 现代 C++ 推荐方式
auto x = 0; // 编译器推断 x 为 int
auto it = myVec.begin(); // 编译器推断 it 为 std::vector<int>::iterator
为什么这样做是更好的选择?
-
正确性
这是使用
auto最重要的原因。auto可以帮助你避免一些难以发现的类型错误。-
保证变量被初始化
int x; // 未初始化,值是未定义的 (UB) Widget w; // 调用了 Widget 的默认构造函数如果使用
auto,就必须提供一个初始值,因为编译器需要根据这个初始值来推断类型。这从语法上就杜绝了“未初始化”的变量。auto x; // 编译错误!必须初始化 auto x = 0; // 正确,x 被初始化为 0,类型为 int -
避免写错复杂的类型
当类型变得复杂时,手动书写不仅繁琐,而且容易出错。
// 手动声明一个处理 int 的 lambda,类型复杂且无法写出 // std::function<bool(int, int)> f = [](int a, int b){ return a > b; }; // 这其实是类型擦除,不是 lambda 的原始类型 // 使用 auto 就简单而精确 auto greater = [](int a, int b) { return a > b; }; // greater 的类型就是这个 lambda 的真实类型使用
auto,编译器会保证变量的类型是绝对正确的,你不会因为手误或理解偏差而写错类型。 -
避免无意的类型转换(性能陷阱)
这是一个非常微妙但重要的点。有时候,你显式声明的类型可能不是你想要的那个,从而导致了不必要的类型转换,甚至影响性能。
书中最经典的例子是
std::vector<bool>。由于 C++ 标准对vector<bool>做了特化,它的operator[]返回的不是一个bool&,而是一个代理对象(proxy object),通常是std::vector<bool>::reference类型。这个代理对象可以隐式转换为bool。std::vector<bool> features(getFeatures()); // 显式声明为 bool bool highPriority = features[5]; // 1. operator[] 返回一个代理对象 // 2. 代理对象隐式转换为 bool // 3. bool 被用来初始化 highPriority // 使用 auto auto highPriority = features[5]; // highPriority 的类型被正确推断为 std::vector<bool>::reference // 这里没有发生从代理对象到 bool 的转换在这个例子中,显式声明为
bool会强制发生一次类型转换,生成一个临时的bool值。而使用auto则直接得到了代理对象本身,避免了这次转换。虽然在这个特定场景下性能差异可能不大,但在更复杂的代理模式中(如表达式模板),这种差异可能是巨大的。auto能确保你得到的是表达式“真正”的类型。
-
-
可维护性
使用
auto可以让代码更容易维护和重构。想象一个函数,它返回一个特定类型的值:
// a_library.h std::map<std::string, int> getSomeMap(); // your_code.cpp std::map<std::string, int> myMap = getSomeMap();现在,库的作者决定优化
getSomeMap,让它返回一个std::unordered_map,因为哈希表的性能更好。// a_library.h (after change) std::unordered_map<std::string, int> getSomeMap();你的代码
your_code.cpp会编译失败,因为类型不匹配了。你必须手动去修改所有调用getSomeMap的地方。但如果你一开始就使用了
auto:// your_code.cpp (with auto) auto myMap = getSomeMap();当
getSomeMap的返回类型改变时,myMap的类型也会自动随之改变。你的代码无需任何修改就能正常工作。这大大简化了代码的重构过程。
item6:auto推导若非己愿,使用显式类型初始化惯用法
auto 推断出的类型并非总是你想要的。
auto 的工作方式是忠实地、精确地推断出初始化表达式的类型。但在某些情况下,表达式的“真实”类型可能是一个我们不希望直接持有的类型,比如一个代理对象(Proxy Object)。
在这些情况下,我们想要的不是表达式本身的类型,而是它可以隐式转换成的那个目标类型。
经典案例:std::vector<bool> 的代理对象
这个例子在 Item 5 的讨论中也提到过,但在 Item 6 中是核心。
C++ 标准库对 std::vector<bool> 进行了空间优化特化。为了节省空间,它内部并不存储 bool(通常占 1 字节),而是用一个比特位(bit)来表示一个布尔值。
这个优化的代价是 operator[] 不能返回一个 bool& (因为 C++ 中没有“比特位的引用”这种东西)。取而代之,它返回一个代理对象,类型为 std::vector<bool>::reference。这个代理对象表现得像一个 bool&,它重载了赋值运算符和向 bool 的类型转换函数。
std::vector<bool> features(getFeatures());
auto highPriority = features[5]; // highPriority 的类型是什么?
根据 auto 的推断规则,highPriority 的类型被精确地推断为 std::vector<bool>::reference。
在大多数情况下,这没问题,因为 std::vector<bool>::reference 可以隐式转换为 bool。但有一种情况是致命的:当 std::vector<bool> 是一个临时对象时。
代理对象 std::vector<bool>::reference 内部通常包含一个指向 vector 内部数据块的指针和一个偏移量。如果这个 vector 是临时的,它在表达式结束时就会被销毁。
std::vector<bool> makeVec() {
return {false, true, false, true, false, true};
}
// ...
auto p = makeVec()[5]; // 危险!
这里发生了什么?
makeVec()返回一个临时的std::vector<bool>对象。[5]对这个临时对象调用,返回一个std::vector<bool>::reference代理对象。- 这个代理对象
p内部持有的指针指向了那个临时的 vector。 - 在分号处,完整的表达式结束,临时的
vector被销毁。 - 现在,
p变成了一个悬空引用 (dangling reference)!它内部的指针指向了一块已经被释放的内存。任何后续对p的使用都是未定义行为(Undefined Behavior)。
在这个场景下,我们真正想要的不是代理对象 std::vector<bool>::reference,而是一个纯粹的 bool 值。
如果用的是bool p,那就会为p专门开辟一块1B的内存,并把零时变量里的值拷贝到p的内存中。
而auto不同的是,p的实际类型是一个std::vector<bool>::reference 代理对象,只是将p的指针指向了临时变量的那块内存。而临时对象在分号之后就已经销毁了。
怎么验证?
#include <iostream>
#include <vector>
std::vector<bool> makeVec() {
return {false, true, false, true, false, true};
}
int main() {
auto p = makeVec()[5];
std::cout << p << std::endl;// 打印结果会是什么?
}

可以看到,打印的结果并不固定。这是因为p的指针指向的那块内存已经被释放了,不是true,已经是未定义的内存了。
怎么修改?
#include <iostream>
#include <vector>
std::vector<bool> makeVec() {
return {false, true, false, true, false, true};
}
int main() {
auto p = static_cast<bool> (makeVec()[5]); // 安全!
// 等价于 bool p = static_cast<bool> (makeVec()[5]);
std::cout << p << std::endl;
}
item7:区别实用()和{}创建对象
{}创建对象的特点
{} 初始化虽然强大,但它有一个“霸道”的特性:只要有可能,它就会优先匹配接收 std::initializer_list 的构造函数。这导致了 {} 和 () 之间三个主要区别:
- 对
std::initializer_list的“贪婪”匹配:这是最令人惊讶和最需要注意的区别。 - 对窄化转换(Narrowing Conversions)的禁止:这是
{}的一个重要安全特性。 - 对“最令人烦恼的解析”(Most Vexing Parse)的免疫:这是
{}的一个便利之处。
对 std::initializer_list 的“贪婪”匹配
这是 Item 7 的核心。规则是:当使用 {} 进行对象构造时,如果类有一个或多个接收 std::initializer_list 的构造函数,编译器会极其强烈地(甚至不惜进行类型转换)优先选择这些构造函数。
我们来看一个经典的例子。假设有一个 Widget 类:
class Widget {
public:
// "普通"构造函数
Widget(int i, bool b) { /* ... */ }
Widget(int i, double d) { /* ... */ }
// 接收 initializer_list 的构造函数
Widget(std::initializer_list<long double> il) { /* ... */ }
// ... 其他函数
};
现在,我们用不同的方式来创建对象:
Widget w1(10, true); // 使用 ()
// 匹配过程:
// 1. 寻找 Widget(int, bool),完美匹配!
// 结果:调用 Widget(int, bool) 构造函数。这符合我们的直觉。
Widget w2{10, true}; // 使用 {}
// 匹配过程:
// 1. 优先寻找接收 std::initializer_list 的构造函数。找到了 Widget(std::initializer_list<long double> il)。
// 2. 检查初始化列表 {10, true} 中的元素能否转换为 long double?
// - 10 (int) -> 10.0 (long double),可以。
// - true (bool) -> 1.0 (long double),可以。
// 3. 转换是合法的,于是**选择此构造函数。
// 结果:调用 Widget(std::initializer_list<long double>) 构造函数。这可能完全不是你的本意!
Widget w3(10, 5.0); // 使用 (),调用 Widget(int, double)
Widget w4{10, 5.0}; // 使用 {},仍然调用 Widget(std::initializer_list<long double>)
为什么会这样?
编译器的重载解析过程在遇到 {} 初始化时,会有一个特殊的“特权阶段”。它会先检查有没有 std::initializer_list 版本的构造函数。只要初始化列表中的实参类型能够(不发生窄化转换地)被隐式转换为 std::initializer_list 中指定的类型,编译器就会毫不犹豫地选择它,而完全忽略其他可能更匹配的“普通”构造函数。
这个特性对于像 std::vector 这样的容器类来说,是符合直觉的:
std::vector<int> v1{10, 20}; // 调用 initializer_list 构造函数,v1 包含两个元素:10 和 20。
std::vector<int> v2(10, 20); // 调用普通构造函数,v2 包含十个元素,每个元素的值都是 20。
在这里,{} 和 () 的行为差异是设计好的,也是我们想要的。但当这个规则应用到像上面 Widget 这样的类时,就会产生意外。
一个特殊情况:如果使用 {} 时,实参类型到 std::initializer_list 的类型转换会导致窄化转换,那么编译器就会放弃 std::initializer_list 构造函数,转而进行正常的重载解析。
禁止窄化转换 (Narrowing Conversions)
窄化转换是指一个值从一种类型转换到另一种类型时,可能会丢失精度或超出目标类型的表示范围。例如,double 转 int,或者一个大的 int 转 char。
使用 () 初始化的传统方式是允许窄化转换的(编译器通常只会给一个警告)。而 {} 初始化则在编译期就禁止这种转换,直接导致编译错误。
double x = 1.2, y = 3.4, z = 5.6;
int sum1(x + y + z); // 合法,但有风险。x+y+z 的结果是 10.2,被截断为 10 赋给 sum1。
// 编译器可能会给一个警告。
int sum2{x + y + z}; // 编译错误!
// double -> int 是一种窄化转换,{} 初始化不允许。
注:
g++ -std=c++14 main.cpp -o main会编译成功,只是会弹出warning
开启严格编译模式g++ -std=c++14 -pedantic-errors main.cpp -o main则会输出error
免疫“最令人烦恼的解析” (Most Vexing Parse)
这是 C++ 语言中一个经典的语法歧义问题。当你想创建一个默认构造的对象时,如果你不小心加上了括号,它就会被编译器解析成一个函数声明。
// 你的意图:创建一个名为 w 的 Widget 对象,使用默认构造函数。
Widget w(); // 糟糕!这不是对象声明!
// 这是声明一个名为 w 的函数,该函数不接受参数,返回一个 Widget 对象。
// 这就是 "Most Vexing Parse"。
为了正确地默认构造一个对象,你必须省略括号:
Widget w; // 正确。调用 Widget 的默认构造函数。
而使用 {} 初始化则完全没有这个歧义问题:
Widget w{}; // 正确且清晰。创建一个名为 w 的 Widget 对象,使用默认构造函数。
因此,在需要调用默认构造函数时,使用 {} 是一种更清晰、更不容易出错的选择。
item8: 优先考虑nullptr而非0和NULL
在 C++11 之前,我们用 0 或者一个宏 NULL 来表示空指针。这两种方式都存在一个根本性的缺陷:它们都不是真正的指针类型。0 是一个 int,而 NULL 通常只是一个被宏定义为 0 或者 ((void*)0) 的东西。这种类型上的模糊性会导致函数重载决议(overload resolution)出现意外。
C++11 引入了一个新的关键字 nullptr,它是一个真正的“空指针常量”,拥有自己独立的类型 std::nullptr_t,从而完美地解决了上述问题。
为什么0和NULL不好?
问题的根源在于 0 和 NULL 的类型歧义。让我们通过一个经典的函数重载例子来理解这个陷阱。
假设我们有三个重载函数,分别用于处理 int、bool 和指针:
void f(int i) {
std::cout << "Called f(int)" << std::endl;
}
void f(bool b) {
std::cout << "Called f(bool)" << std::endl;
}
void f(void* ptr) {
std::cout << "Called f(void*)" << std::endl;
}
现在,我们尝试用 0 和 NULL 来调用我们期望的指针版本 f(void*):
f(0); // 我们期望调用哪个版本?
f(NULL); // 我们又期望调用哪个版本?
使用 0 的问题:
0 的字面量类型是 int。根据 C++ 的重载决议规则,编译器会选择最匹配的版本。
f(0)传入的是一个int。f(int)是一个完美匹配。f(bool)需要int->bool转换。f(void*)需要int(空指针常量)->void*转换。
完美匹配的优先级最高。 因此,f(0) 会调用 f(int)!
输出:
Called f(int)
这完全违背了程序员“我想传递一个空指针”的意图。这是一个非常隐蔽且危险的 Bug。
使用 NULL 的问题
NULL 只是一个宏,它的具体定义是实现相关的。通常,它被定义为以下两种之一:
#define NULL 0
// 或者
#define NULL 0L
// 或者在 C++ 中,有时是
#define NULL ((void*)0)
- 如果
NULL被定义为0或0L:那么f(NULL)就等同于f(0)或f(0L)。它依然会因为类型匹配问题而去调用f(int)(或者一个f(long)的重载),而不是我们想要的指针版本。 - 如果
NULL被定义为((void*)0):情况会好一些。f(NULL)会正确调用f(void*)。但是,这种定义方式本身也有问题,比如它不能被用于需要整型类型的上下文,而且宏本身在现代 C++ 中也是不被推荐的。
最糟糕的是,你无法确定 NULL 在你的平台和编译器上到底是什么,这使得依赖 NULL 的代码不具备良好的可移植性和可预测性。
解决方案:nullptr
C++11 引入 nullptr 来一劳永逸地解决这个问题。
nullptr是一个关键字,不是宏。- 它的类型是
std::nullptr_t。 std::nullptr_t类型可以隐式转换为任何类型的指针(如int*,Widget*,std::string*等)。std::nullptr_t不能隐式转换为整型(int,bool除外,它可转换为false)。
现在,我们用 nullptr 来调用上面的重载函数:
f(nullptr);
重载决议过程如下:
nullptr的类型是std::nullptr_t。f(int):std::nullptr_t无法转换为int。此路不通。f(bool):std::nullptr_t可以转换为bool(false)。这是一个合法的转换。f(void*):std::nullptr_t可以转换为void*。这是一个合法的转换。
现在我们有了两个合法的转换。但是,从 std::nullptr_t 到指针类型的转换被认为是比到 bool 更好的匹配。因此,编译器会毫不犹豫地选择指针版本。
输出:Called f(void*)
这完全符合我们的意图!nullptr 解决了类型歧义,让代码的行为变得正确和可预测。
nullptr的其他优势
当你在模板中使用 0 或 NULL 时,模板类型推导可能会将其推导为整型(int 或 long),这通常会导致编译错误或非预期的行为。而 nullptr 的类型是 std::nullptr_t,模板可以正确地处理它。
template<typename F, typename T>
void forwarder(F f, T arg) {
f(arg);
}
forwarder(f, 0); // T 被推导为 int,调用 f(int)
forwarder(f, NULL); // T 可能被推导为 int 或 long,调用 f(int)
forwarder(f, nullptr); // T 被推导为 std::nullptr_t,正确调用 f(void*)
规则很简单:
在现代 C++ 代码中,永远不要使用 0 或 NULL 来表示空指针。始终使用 nullptr。这是一个没有例外、可以无脑遵守的规则。
item9:优先考虑别名声明而非typedef
这个条款是 C++11 引入的一项重要的语言改进。它建议我们在为类型创建别名(alias)时,放弃传统的 typedef 关键字,转而使用新的 using 语法。虽然 typedef 仍然可用且有效,但 using 提供了更好的可读性,并且能够完成 typedef 无法完成的任务——别名模板(alias templates)
对于更复杂的类型,比如函数指针,using 的可读性优势更加明显。
使用 typedef 创建函数指针别名:
// FP 是一个指向“接受 int 和 const std::string&,返回 void”的函数的指针类型
typedef void (*FP)(int, const std::string&);
使用 using 创建函数指针别名:
// FP 是一个指向“接受 int 和 const std::string&,返回 void”的函数的指针类型
using FP = void (*)(int, const std::string&);
这种写法将别名 FP 和它所代表的复杂类型清晰地分开了,FP 在左边,类型在右边,一目了然。
using 可以被模板化,从而创建别名模板,而 typedef 不能
场景:我们想要一个自定义的 std::vector
假设我们正在开发一个项目,需要频繁使用一个带有自定义内存分配器 MyAlloc 的 std::vector。我们希望创建一个别名,让 MyVector<T> 就代表 std::vector<T, MyAlloc<T>>。
使用 typedef 的尝试(失败的):
你可能会想这么写,但这在语法上是不合法的:
template<typename T>
typedef std::vector<T, MyAlloc<T>> MyVector; // 编译错误!typedef 不能被模板化
C++11 的别名模板完美地解决了这个问题。
template<typename T>
using MyVector = typename std::vector<T, MyAlloc<T>>;
// 使用时:
MyVector<int> myVec; // 简单、直观,就像使用普通模板一样
item10:优先考虑限域枚举而非未限域枚举
这个条款强烈建议在 C++11 及以后的代码中,使用新的 enum class (或 enum struct) 来代替旧的 enum。这是一个关于类型安全、作用域控制和代码清晰度的重要改进。
传统的 C-style enum (现在称为不限作用域枚举 Unscoped Enum) 存在几个严重的设计缺陷,这些缺陷常常导致命名冲突和类型安全漏洞。C++11 引入的作用域内枚举 (Scoped Enum),通过 enum class 关键字,完美地修复了这些问题。
不限作用域枚举的三大缺陷
1. 枚举成员污染所在作用域
不限作用域枚举的枚举成员会“泄漏”到其定义所在的整个作用域中,就像普通变量一样。
// a_library.h
enum Color { Red, Green, Blue };
// my_code.h
enum TrafficLight { Green, Yellow, Red }; // 编译错误!
int main() {
Color c = Red; // 是哪个 Red?
TrafficLight t = Green; // 是哪个 Green?
}
这段代码无法编译,因为 Red 和 Green 在同一个作用域(这里是全局作用域)中被重复定义了。为了解决这个问题,程序员们不得不使用各种变通方法,比如给枚举成员加上前缀:
enum Color { COLOR_RED, COLOR_GREEN, COLOR_BLUE };
enum TrafficLight { TRAFFIC_LIGHT_GREEN, TRAFFIC_LIGHT_YELLOW, TRAFFIC_LIGHT_RED };
这种方法很丑陋,而且完全是手动劳动,容易出错。
2. 隐式转换为整型,破坏类型安全
不限作用域枚举的成员可以被隐式地转换为任何整型(int, char, unsigned int 等),但反过来不行(从整型到枚举需要显式转换)。
这种单向的隐式转换会破坏类型安全,导致一些在逻辑上毫无意义的操作能够通过编译。
enum Color { Red, Green, Blue };
enum AlertLevel { Low, Medium, High };
Color c = Red; // c 的值是 0
AlertLevel a = High; // a 的值是 2
// 编译通过,但逻辑上毫无意义!
// 你在比较一个颜色和一个警报级别。
if (c < a) {
// ... 这个 if 语句会执行,因为 0 < 2
std::cout << "Color is less than AlertLevel!" << std::endl;
}
编译器不会阻止你这样做,因为它看到的只是两个整数在比较。这可能导致非常隐蔽的逻辑错误。你本意是想比较同类型的东西,却因为隐式转换,错误地比较了两个完全不相关的值。
3. 难以进行前向声明
前向声明(Forward Declaration)是C++中的一种技术,用于在声明某个实体(通常是类、函数、变量等)的名称而无需提供其详细定义。 前置声明的目的是为了告诉编译器某个实体的存在,以便在稍后的代码中引用它,而不必在声明的地方提供完整的定义。 这可以提高编译速度和减少编译依赖性
前向声明在 C++ 中对于减少编译依赖、加快编译速度非常重要。你想在头文件中只声明一个枚举,而在源文件中定义它。
对于不限作用域枚举,默认情况下无法进行前向声明。因为编译器不知道这个 enum 底层应该用多大的整型来存储(是 int? char? unsigned int?)。
enum Color; // 编译错误!编译器不知道 Color 的大小。
虽然 C++11 之后,你可以为不限作用域枚举指定底层类型,从而让它能够被前向声明:
// a.h
enum Color : unsigned char; // OK in C++11
void use_color(Color c);
// a.cpp
enum Color : unsigned char { Red, Green, Blue };
void use_color(Color c) { /* ... */ }
但这需要你手动指定类型,而且并没有解决前两个核心缺陷。
作用域内枚举
C++11 的 enum class (或者它的同义词 enum struct) 干净利落地解决了上述所有问题。
枚举成员被严格限定在枚举的作用域内
enum class 的成员不会泄漏到外部作用域。你必须通过 枚举名::成员名 的方式来访问它们。
// a_library.h
enum class Color { Red, Green, Blue };
// my_code.h
enum class TrafficLight { Green, Yellow, Red }; // 完全没问题!
int main() {
// 必须使用作用域解析符::
Color c = Color::Red;
TrafficLight t = TrafficLight::Green;
// 下面的代码无法编译,因为 Red 和 Green 不在全局作用域中
// Color c2 = Red; // 错误!
// 不同枚举的同名成员不会冲突
if (c == Color::Red && t == TrafficLight::Red) {
// ...
}
}
强类型,禁止隐式转换为整型
弱、强类型指的是语言类型的系统的类型检查的严格程度。弱类型相对于强类型来说类型检查更不严格,比如说允许变量类型的隐式转换,允许强制类型转换等等。强类型语言一般不允许这么做。
enum class 是强类型的。它的值不能被隐式地转换为整型。
enum class Color { Red, Green, Blue }; // Red 的值是 0
enum class AlertLevel { Low, Medium, High }; // High 的值是 2
Color c = Color::Red;
AlertLevel a = AlertLevel::High;
// if (c < a) { ... } // 编译错误!
// 错误信息:no match for ‘operator<’ (operand types are ‘Color’ and ‘AlertLevel’)
编译器现在可以帮你捕捉到这种逻辑错误了。如果你真的需要获取其底层的整数值(比如用于打印或序列化),你必须进行显式的类型转换,这表明了你的真实意图。
int colorValue = static_cast<int>(c); // 显式转换,OK
std::cout << colorValue << std::endl; // 输出 0
天生支持前向声明
enum class 的底层类型在 C++11 标准中默认为 int。因为它的底层类型是确定的,所以它可以被轻松地前向声明。
// my_widget.h
enum class Color; // OK!编译器知道它的大小(默认为 int)
void setBackgroundColor(Color c);
你也可以像不限作用域枚举一样,手动指定它的底层类型,这在需要精确控制内存布局或与 C API 交互时非常有用。
// 使用 1 字节存储
enum class Status : std::uint8_t {
Good,
Warning,
Error
};
| 特性 | 不限作用域枚举 (enum) |
作用域内枚举 (enum class) |
|---|---|---|
| 作用域 | 成员污染外部作用域 | 成员限定在枚举作用域内 (Color::Red) |
| 类型安全 | 弱类型,可隐式转为整型 | 强类型,禁止隐式转换,需 static_cast |
| 前向声明 | 默认不行 (需在C++11后手动指定类型) | 可以 (默认底层类型为int) |
在 C++11 或更高版本的代码中,无条件地优先使用 enum class。它更安全、更清晰、更健壮。只有在极少数需要与旧的 C API 交互,而那个 API 又需要一个可以隐式转换为 int 的枚举类型时,你才可能需要退回到使用不限作用_域枚举。在所有其他情况下,enum class 都是更好的选择。
item11:优先考虑使用deleted函数而非使用未定义的私有声明
有时,我们不希望某些函数被调用。最经典的例子就是禁止类的拷贝。C++ 编译器会为我们自动生成一些函数(所谓的“特殊成员函数”),比如拷贝构造函数和拷贝赋值运算符。如果我们的类设计(例如,管理着独占资源,像文件句柄或网络套接字)不允许拷贝,我们就必须阻止编译器生成这些函数,并禁止任何人调用它们。
在 C++11 之前和之后,我们有两种方法来做这件事,而 C++11 的 = delete 是一个全方位的优越选择。
私有的未定义函数
在 C++11 出现之前,禁止一个成员函数(特别是拷贝构造/赋值)的标准做法是:
- 将该函数声明为
private。 - 只声明,不定义(不提供函数体实现)。
例子:一个不可拷贝的 Widget 类
class Widget {
private:
// 1. 声明为 private
// 2. 不提供定义 (no implementation)
Widget(const Widget&);
Widget& operator=(const Widget&);
public:
Widget() = default;
// ... 其他接口
};
这种方法是如何工作的?
它利用了两层防护:
- 对于外部代码:当外部代码试图拷贝
Widget对象时,例如Widget w2 = w1;,编译器会检查访问权限。因为它发现拷贝构造函数是private的,所以会立即给出一个编译期错误 (compile-time error)。这是我们想要的效果。 - 对于内部代码 (成员函数或
friend类):如果一个Widget的成员函数或友元函数试图拷贝Widget对象,它有权限访问private成员,所以编译会通过。但是,由于我们没有提供函数的定义,程序在链接阶段会找不到这个函数的实现,从而导致一个链接期错误 (link-time error),通常是 “undefined reference toWidget::Widget(const Widget&)“。
这种方法的缺陷:
- 错误信息不友好且滞后:链接期错误通常比编译期错误更难排查。它发生在编译过程的最后阶段,而且错误信息可能不如编译器错误那样直接指向出错的调用代码行。
- 适用范围有限:这种技巧只能用于类的成员函数。它无法禁止一个非成员函数(自由函数)或一个特定的模板实例化。
- 意图不明确:
private的本意是“封装实现细节”,而不是“禁止使用”。这是一种“绕路”的技巧(idiom),而不是直接的语言特性。
=delete删除函数
C++11 引入了一种全新的、更直接的语法来禁止函数的使用:在函数声明后加上 = delete;。
= delete; 的含义:这个函数是被删除的。它存在,但不能以任何方式被调用。任何试图调用它的代码都会导致一个编译期错误。
class Widget {
public:
// 显式地将它们声明为 public(习惯做法)然后删除
Widget(const Widget&) = delete;
Widget& operator=(const Widget&) = delete;
Widget() = default;
// ... 其他接口
};
- 注意:被删除的函数通常声明为
public。这是一种好的实践,因为客户端代码通常会先检查public接口。当它找到这个函数但发现它被删除了,编译器会立即给出一个清晰的错误信息。如果声明为private,访问控制的错误信息可能会先于“函数被删除”的错误信息出现。
这种方法是如何工作的?
非常简单直接:任何代码——无论是外部代码、成员函数还是友元函数——只要试图调用一个被 delete 的函数,都会立即得到一个清晰的编译期错误。编译器会明确告诉你:“你正在尝试使用一个已被删除的函数”。
=delete可以用于任何函数,而不仅仅是成员函数
这是 = delete 的一个巨大优势。你可以删除任何函数,包括非成员函数。
场景:假设你有一个函数 isLucky(int),但你不想让它被 bool 或 char 类型的参数调用,因为这种隐式转换可能会隐藏 bug。
bool isLucky(int number); // 我们想要这个版本
// 禁止传入 bool,因为 true/false 转换成 1/0 的意义可能不明确
bool isLucky(bool b) = delete;
// 禁止传入 char,防止不小心传入一个字符
bool isLucky(char c) = delete;
int main() {
isLucky(42); // OK
isLucky(true); // 编译错误!尝试使用一个被删除的函数
isLucky('a'); // 编译错误!
}
=delete可以用于禁止特定的模板实例化
这是 = delete 最强大的功能之一。你可以有一个通用的函数模板,然后显式地删除你不希望支持的特定类型实例化版本。
场景:你有一个处理指针的模板,但你希望禁止用户传入 void*(不安全)或 char*(可能是 C 风格字符串,应该用 std::string 处理)。
template<typename T>
void processPointer(T* ptr) {
// ... 对有类型的指针进行处理
}
// 显式删除 void* 版本
template<>
void processPointer<void>(void* ptr) = delete;
// 显式删除 char* 版本
template<>
void processPointer<char>(char* ptr) = delete;
// 显式删除 const char* 版本
template<>
void processPointer<const char>(const char* ptr) = delete;
int main() {
int x = 10;
processPointer(&x); // OK
void* p = &x;
processPointer(p); // 编译错误!
const char* str = "hello";
processPointer(str); // 编译错误!
}
总结
| 特性 | 私有未定义函数 (旧方法) | = delete 删除函数 (新方法) |
|---|---|---|
| 适用范围 | 仅限类的成员函数 | 任何函数 (成员/非成员/模板实例化) |
| 错误报告时机 | 编译期 (外部调用) 或 链接期 (内部/友元调用) | 编译期 (所有情况) |
| 错误信息 | “private access” 或 “undefined reference” | “function … has been deleted” (清晰明确) |
| 意图 | 是一种技巧/惯用法 | 直接的语言特性,意图清晰 |
最终规则:
在 C++11 及以后的代码中,当你需要禁止一个函数的使用时,永远优先使用 = delete。它更安全、更清晰、功能更强大、适用范围更广。私有未定义函数的方法已经是一种过时的技术,应该在现代 C++ 代码中被完全取代。
item12:使用override声明重写函数
没有 override 的世界有多危险?
在 C++11 之前,如果你想重写一个虚函数,你只需要在派生类中声明一个和基类虚函数签名(函数名、参数列表、const 属性等)完全相同的函数即可。
这听起来简单,但“完全相同”这个要求非常脆弱,很容易在不经意间被打破,而编译器却不会给你任何警告。
以下是几种常见的“意外”:
函数名拼写错误
class Base {
public:
virtual void doWork() { /* ... */ }
};
class Derived : public Base {
public:
// 程序员的意图是重写,但不小心打错了字
virtual void doWrok() { /* ... */ } // "Work" -> "Wrok"
};
结果:这段代码可以完美编译。但 Derived::doWrok 并没有重写 Base::doWork,它只是一个全新的、与基类无关的虚函数。当你通过基类指针调用 doWork 时,永远不会执行到派生类的版本,多态性被悄无声息地破坏了。
const 属性不匹配
class Base {
public:
virtual void doWork() const { /* ... */ }
};
class Derived : public Base {
public:
// 基类是 const 成员函数,这里忘记加 const
virtual void doWork() { /* ... */ }
};
结果:编译通过,但 Derived::doWork 并没有重写 Base::doWork,因为它们的 const 属性不同。
基类函数签名变更
假设一开始代码是正确的:
// in Base.h
class Base {
public:
virtual void doWork() { /* ... */ }
};
// in Derived.h
class Derived : public Base {
public:
virtual void doWork() { /* ... */ } // 正确重写
};
后来,Base 类的维护者决定给 doWork 函数增加一个参数,并提供默认值以保持向后兼容:
// in Base.h (modified)
class Base {
public:
virtual void doWork(int param = 0) { /* ... */ } // 签名变了!
};
结果:Derived::doWork() 现在不再重写任何基类函数了!它变成了一个独立的函数。你的整个项目仍然可以编译,但所有依赖于 doWork 多态性的地方都会开始出现奇怪的、错误的行为。
解决方案:override 关键字
C++11 的 override 完美地解决了以上所有问题。它告诉编译器:“我明确地声明,这个函数必须重写一个基类的虚函数。请帮我检查一下!”
我们用 override 来改写上面的例子:
class Base {
public:
virtual void doWork() const { /* ... */ }
};
class Derived : public Base {
public:
// 程序员犯了两个错误:拼写错误 + 忘记 const
virtual void doWrok() override { /* ... */ }
};
现在,当你尝试编译这段代码时,编译器会立刻报错,可能的消息是:
'doWrok' marked 'override' but does not override any base class method.
(’doWrok’ 被标记为 override,但它没有重写任何基类方法。)
编译器强制你修正错误,直到函数的签名与基类中的某个虚函数完全匹配为止。
正确的写法:
class Base {
public:
virtual void doWork() const { /* ... */ }
};
class Derived : public Base {
public:
// 完全匹配,并且用 override 明确意图
virtual void doWork() const override { /* ... */ }
};
final关键字
与 override 相关的还有一个 C++11 关键字是 final。它有两个用途:
-
用于函数:阻止派生类进一步重写。
class A { public: virtual void foo(); }; class B : public A { public: void foo() final override; // B::foo 重写了 A::foo,并且是最终版本 }; class C : public B { public: // void foo() override; // 编译错误!B::foo 是 final 的 }; -
用于类:阻止类被继承。
class Sealed final { /* ... */ }; // class DerivedFromSealed : public Sealed {}; // 编译错误!Sealed 不能被继承
总结:
override的好处:- 提高代码可读性:读者一眼就能看出这个函数是用来重写的。
- 强制编译器检查:将隐蔽的运行时多态错误,转变为清晰的编译时错误。
- 提升代码健壮性:防止因基类变更而导致的意外行为。
- 最佳实践:养成习惯,只要你打算重写一个虚函数,就在函数声明的末尾加上
override。这是现代 C++ 编程中一个简单却极其有效的防御性编程技巧。
item13:优先考虑const iterator而非iterator
尽可能地使用 const_iterator 进行只读操作,只有当你确实需要修改容器中的元素时,才使用 iterator。
这背后的原则是“最小权限原则” (Principle of Least Privilege):只授予代码完成其任务所必需的最小权限。如果你的代码只需要读取数据,就不应该给予它写入数据的能力。
iterator 和 const_iterator 的区别
iterator |
像一个可读可写的指针 (T*)。你可以通过它读取元素,也可以修改它指向的元素。 |
|---|---|
const_iterator |
像一个只读的指针 (const T*)。你可以通过它读取元素,但不能修改它指向的元素。 |
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {10, 20, 30};
// --- 使用 iterator (可读可写) ---
std::vector<int>::iterator it = v.begin();
std::cout << "Original value: " << *it << std::endl; // 读取: OK
*it = 99; // 写入/修改: OK!
std::cout << "Modified value: " << *it << std::endl; // v 现在是 {99, 20, 30}
// --- 使用 const_iterator (只读) ---
std::vector<int>::const_iterator cit = v.cbegin(); // 使用 cbegin() 获取 const_iterator
std::cout << "Value via const_iterator: " << *cit << std::endl; // 读取: OK
// *cit = 100; // 写入/修改: 编译错误!
// 编译器会报错,类似: "assignment of read-only location"
return 0;
}
注意!const_iterator it不能用const auto it或者auto const it来替代!
const auto it或者auto const it是相同的意思,表达的是it本身(地址)是一个常量,而它指向的内容并不是常量。
而const_iterator it表达的意思是:it指向的内容是一个常量,不允许修改。it本身可以修改
为什么要优先选择 const_iterator?
考虑一个函数,它的功能是打印 vector 的内容:
// 这个函数承诺不会修改传入的 'container'
void print_elements(const std::vector<int>& container) {
// 错误的做法:
// std::vector<int>::iterator it = container.begin(); // 编译错误!
// 你不能从一个 const 容器中获取一个非 const 的 iterator。
// 因为如果允许了,你就可以通过 it 修改 const 容器了,这违背了 const 承诺。
// 正确的做法:
std::vector<int>::const_iterator cit = container.cbegin(); // OK
// 或者更现代的写法:
// auto cit = container.cbegin(); // auto 推导出的类型是 const_iterator
for (; cit != container.cend(); ++cit) {
std::cout << *cit << " ";
}
std::cout << std::endl;
}
通过使用 const_iterator,你的函数可以同时接受 const 和非 const 的容器,使其适用性更广。如果你用了 iterator,这个函数就无法处理 const 容器了。
当你的意图只是遍历和读取时,使用 const_iterator 就像上了一道保险。编译器会帮你检查,确保你不会在代码的某个角落意外地修改了容器中的值。这使得代码的意图更加清晰:看到 const_iterator,任何阅读代码的人都会立刻明白这里的操作是只读的。
在 C++11 之前,const_iterator 的类型名写起来很长,有点麻烦。但 C++11 引入了 cbegin() 和 cend() 成员函数,以及 auto 关键字,极大地简化了这一过程。
container.begin(): 如果container是非const的,返回iterator;如果是const的,返回const_iterator。container.cbegin(): 无论container是否是const,永远返回const_iterator。
std::vector<int> numbers = {1, 2, 3};
// 当你只需要读取时,明确使用 cbegin
for (auto it = numbers.cbegin(); it != numbers.cend(); ++it) {
std::cout << *it; // 读取 OK
// *it = 5; // 编译错误,正如你所期望的
}
// 当你需要修改时,才使用 begin
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
*it *= 2; // 修改 OK
}
cbegin() 是向编译器和代码读者传达“我在这里是只读”意图的最清晰方式。
一个常见的混淆点:const_iterator vs. const iterator
这两者是完全不同的东西,就像 const T* 和 T* const 的区别一样。
const_iterator: 一个指向常量的迭代器。你不能修改它指向的元素,但可以移动迭代器本身(例如it++)。
std::vector<int>::const_iterator cit = v.cbegin();
// *cit = 10; // 错误!不能修改所指元素
++cit; // 正确!可以移动迭代器
const iterator: 一个常量迭代器。迭代器本身不能被移动去指向别处,但你可以修改它当前指向的元素(如果它是一个非const的iterator的话)。
std::vector<int> v = {1, 2};
const std::vector<int>::iterator it = v.begin();
*it = 10; // 正确!可以修改所指元素
// ++it; // 错误!不能移动迭代器本身
在实践中,const iterator 很少使用,我们通常关心的是 const_iterator。
记住这个简单的规则:默认使用 cbegin(),除非你真的需要修改元素
item14:如果函数不抛出异常请使用noexcept
什么是 noexcept?
想象你在进行一项名为“程序运行”的实验。 以前(C++98 时代),函数就像是一个随时可能爆炸的实验室。编译器为了安全,不得不时刻准备着“如果炸了怎么办”,这需要记录很多额外的信息(unwindable state),就像我要时刻准备着拿灭火器一样。
而 noexcept 就像是你跟编译器签的一份“绝对安全协议”。 你告诉编译器:“放心吧,这个函数绝对不会爆炸(抛异常)。” 既然你都敢签协议了,编译器就可以把手里的灭火器扔掉,甚至把防火门都拆了——这就意味着生成的机器码更少,运行速度更快!
在 C++11 里,我们引入了移动语义(Move Semantics),也就是 Item 23 讲的那个。 假设你有一个装满重物的箱子(std::vector),现在箱子满了,你需要换个大仓库。
-
如果没有
noexcept(保守派):std::vector会非常怂。它在搬家的时候,因为怕搬运过程中出事(抛异常),它不敢直接把旧仓库的东西“瞬移”过去,而是会选择把每个东西都复制一遍放到新仓库,然后再销毁旧的。后果: 慢!极其慢!就像是你明明可以直接把实验器材抱走,却非要重新买一套一模一样的。
-
如果你加了
noexcept(激进派):std::vector一看你的移动构造函数上有noexcept签名,它就放心了:“既然你也说了不会出事,那我就不复制了,直接移动!”后果: 效率爆炸提升!特别是在容器扩容的时候,原本的“全部拷贝”变成了“全部移动”。
例:std::vector的扩容机制
当 std::vector 的容量(capacity)不够用,需要 push_back 新元素时,它会开辟一块更大的内存,然后把旧内存里的元素迁移过去。
关键点来了: 它是“搬过去”(Move)还是“抄过去”(Copy)?
C++ 标准库为了保证强异常安全性(Strong Exception Guarantee),有一个很保守的策略:
如果移动构造函数可能抛出异常(没加
noexcept),为了防止搬运搬到一半突然炸了导致数据丢失,vector会选择放弃移动,直接复制。
只有当你明确承诺 noexcept,它才敢大胆地使用 Move。
class SlowObject {
public:
SlowObject() {}
// 复制构造函数
SlowObject(const SlowObject&) {
std::cout << "Copying SlowObject (好累...)\n";
}
// 移动构造函数(注意:这里没加 noexcept!)
// 即使你写了移动逻辑,vector 也不敢用!
SlowObject(SlowObject&&) {
std::cout << "Moving SlowObject (瞬移!)\n";
}
};
class FastObject {
public:
FastObject() {}
// 复制构造函数
FastObject(const FastObject&) {
std::cout << "Copying FastObject (好累...)\n";
}
// 移动构造函数(加了 noexcept!)
// 这是一个“不会失败的承诺”
FastObject(FastObject&&) noexcept {
std::cout << "Moving FastObject (瞬移!)\n";
}
};
int main() {
std::cout << "--- 测试 SlowObject (没加 noexcept) ---\n";
std::vector<SlowObject> vSlow;
vSlow.reserve(2);
vSlow.emplace_back(); // 放第1个
vSlow.emplace_back(); // 放第2个 (满了)
// 关键时刻:再放第3个,触发扩容!
// 旧的两个元素需要迁移到新内存
std::cout << "Triggering resize:\n";
vSlow.emplace_back();
std::cout << "\n--- 测试 FastObject (加了 noexcept) ---\n";
std::vector<FastObject> vFast;
vFast.reserve(2);
vFast.emplace_back();
vFast.emplace_back();
// 关键时刻:触发扩容
std::cout << "Triggering resize:\n";
vFast.emplace_back();
}
结果:
--- 测试 SlowObject (没加 noexcept) ---
Triggering resize:
Copying SlowObject (好累...)
Copying SlowObject (好累...)
--- 测试 FastObject (加了 noexcept) ---
Triggering resize:
Moving FastObject (瞬移!)
Moving FastObject (瞬移!)
为移动构造函数、移动赋值运算符和 swap 函数加上 noexcept,对于使用标准库容器的性能来说,是至关重要的。
noexcept 的用法和规则
-
noexcept作为修饰符:void f() noexcept; // f 承诺不抛出异常 -
noexcept作为条件运算符 (noexcept(expression)): 这是一个编译期的运算符,它返回一个bool类型的constexpr值。如果expression被编译器分析为不会抛出任何异常,它就返回true,否则返回false。int i; noexcept(i++); // 返回 true,因为 int 的自增不抛异常 noexcept(std::string()); // 返回 true,默认构造函数不抛异常 noexcept(std::vector<int>().push_back(1)); // 返回 false,push_back 可能会因内存分配失败而抛异常 -
条件
noexcept(noexcept(...)): 这是noexcept最强大的用法,尤其是在模板编程中。你可以让一个函数的noexcept状态依赖于它内部调用的操作。template<typename T, size_t N> void swap(T (&a)[N], T (&b)[N]) noexcept(noexcept(std::swap(*a, *b))) { // 这个 swap 函数是 noexcept 的,当且仅当 // 对数组内单个元素调用 std::swap 是 noexcept 的。 // ... }告诉编译器:“如果
std::swap(*a, *b)不抛异常,那我也就不抛异常”。
如果承诺了noexcept却抛出了异常
void doDangerousThing() noexcept { // 承诺不抛异常
throw std::runtime_error("Ha! I lied!"); // 实际上抛了
}
int main() {
try {
doDangerousThing();
} catch (...) {
// 不能捕获异常!
std::cout << "Caught it!\n";
}
return 0;
}
程序直接 Crash,输出类似于 terminate called after throwing an instance of...。 那个 catch 块永远不会执行。 编译器看到 noexcept 后,可能根本就没有生成用于捕获异常的堆栈展开(Stack Unwinding)代码。一旦出事,唯一的路就是 std::terminate
item15:尽可能的使用constexpr
constexpr对象
从概念上来说,
constexpr表明一个值不仅仅是常量,还是编译期可知的。
如果你能在编译阶段就把结果算出来,意味着什么?
- 运行时耗时为 0:程序跑起来的时候,结果已经在那了,根本不用算。
- 更广泛的用途:很多地方只能填“编译期常量”,比如数组的大小、模板的参数、
switch语句的case标签。普通变量根本进不去,但constexpr可以!
int sz = 10; // 普通变量
// sz 的值在编译期是未知的(虽然这里看着像10,但编译器认为它可能会变)
const auto constSize = sz; // 正确,constSize 是只读的
// std::array<int, constSize> data; // ❌ 错误!编译器报错!
// 因为编译器说:“运行的时候我才知道 constSize 是几,现在我怎么给你开数组?”
constexpr auto exprSize = 10; // 正确,编译期已知
std::array<int, exprSize> data; // ✅ 完美!编译器很高兴
constexpr函数
constexpr 函数不仅能用于编译期计算,它还有一种“自适应”的能力。
- 当你喂给它编译期常量时: 它会在编译期算出结果,变成一个常量。
- 当你喂给它运行时变量时: 它就退化成一个普通的函数,在运行时计算。
// constexpr 函数
// 在 C++11 中限制很多,通常只能写一行 return
// 但在 C++14 及以后,你可以写循环、判断,随你便
constexpr int pow(int base, int exp) noexcept {
auto result = 1;
for (int i = 0; i < exp; ++i) result *= base;
return result;
}
int main() {
// 场景 A:全部是编译期常量
constexpr auto numCond = 5;
// 编译器在编译阶段就算出了 2^5 = 32
// 这一行代码在生成的二进制文件里,直接就是 std::array<int, 32>
std::array<int, pow(2, numCond)> results;
// 场景 B:参数包含运行时变量
int x = 10; // 运行时才知道
int y = 3;
// 没问题!它会自动降级为普通函数调用,在运行时计算 10^3
auto val = pow(x, y);
return 0;
}
如果你设计一个类,把它的构造函数和成员函数都标记为 constexpr,那么这个类的对象甚至可以在编译期被创建、操作!
class Point {
public:
// 构造函数是 constexpr
constexpr Point(double xVal = 0, double yVal = 0) noexcept
: x(xVal), y(yVal) {}
// getter 也是 constexpr
constexpr double xValue() const noexcept { return x; }
constexpr double yValue() const noexcept { return y; }
// C++14 开始,setter 也可以是 constexpr(修改局部对象)
constexpr void setX(double newX) noexcept { x = newX; }
private:
double x, y;
};
// 一个计算中点的 constexpr 函数
constexpr Point midpoint(const Point& p1, const Point& p2) noexcept {
return { (p1.xValue() + p2.xValue()) / 2,
(p1.yValue() + p2.yValue()) / 2 };
}
int main() {
constexpr Point p1(9.4, 27.7);
constexpr Point p2(28.8, 5.3);
// 这一步计算,在编译生成 exe 之前就已经完成了!
// 编译器直接算出了中点,并把它“烧录”进了程序里。
constexpr auto mid = midpoint(p1, p2);
// 甚至可以用这个计算结果去定义别的常量
static_assert(mid.xValue() == 19.1, "Calculation error!");
}
这有什么用? 这意味着初始化的开销完全被消除了。对于嵌入式系统或者对性能要求极高的场景,这简直就是魔法
item16:让const成员函数线程安全
这是一个在多线程编程中极其重要的概念。它揭示了 C++ const 关键字在并发环境下的一个微妙但关键的含义:从调用者的角度来看,const 成员函数不仅意味着不改变对象的可观察状态,还隐含着一个承诺——它可以被多个线程同时安全地调用。
在单线程世界里,const 成员函数的意义很明确:它是一个“只读”操作,不会修改对象的任何成员变量。编译器会强制执行这一点(这被称为 bitwise constness,位级常量性)。
但是,有时候为了实现某些优化(如缓存、懒加载),我们希望 const 函数能够修改一些内部的、对外部不可见的成员。这时我们会使用 mutable 关键字来突破编译器的限制。这被称为 logical constness(逻辑常量性),即对象对外的逻辑状态没变,但内部的物理表示变了。
在C++中mutable关键字是为了突破const关键字的限制,被mutable关键字修饰的成员变量永远处于可变的状态,即使是在被const修饰的成员函数中。
问题来了:当多个线程同时调用同一个对象的同一个 const 成员函数时,如果这个函数内部正在修改一个 mutable 成员,就会发生数据竞争 (data race),从而导致未定义行为 (Undefined Behavior)。
Item 16 的核心论点是:你必须确保你的 const 成员函数是线程安全的。 如果它内部确实需要修改数据,那么这些修改必须被同步(例如,使用互斥锁 std::mutex 或原子操作 std::atomic)。
多线程竞争
例:
#include <vector>
class Polynomial {
public:
std::vector<double> getRoots() const {
if (!rootsAreValid) { // 检查缓存是否有效
// ... 执行昂贵的根计算 ...
rootVals = { /* 计算出的根 */ }; // 1. 写入缓存
rootsAreValid = true; // 2. 标记缓存有效
}
return rootVals;
}
private:
mutable bool rootsAreValid{false}; // 缓存是否有效的标志
mutable std::vector<double> rootVals; // 缓存的根
// ... 其他代表多项式的成员
};
getRoots()被声明为const,因为它从逻辑上不改变多项式本身(系数等)。- 为了能实现缓存,
rootsAreValid和rootVals必须声明为mutable,这样才能在const函数内修改它们。
在单线程中,这完美工作。但在多线程中,这是灾难性的:
数据竞争场景:
- 线程 A 调用
poly.getRoots()。它检查rootsAreValid,发现是false,于是进入if块,准备开始计算。 - 线程切换!
- 线程 B 也调用
poly.getRoots()。它也检查rootsAreValid,发现它仍然是false(因为线程 A 还没来得及修改它),于是也进入if块。 - 现在,两个线程都在执行昂贵的计算,这是重复劳动。
- 更糟糕的是,线程 A 和线程 B 将会无保护地写入
rootVals和rootsAreValid。这是一个典型的数据竞争。哪个线程的写入会“获胜”是未知的,rootVals的最终内容可能是损坏的,程序可能会崩溃。
如何实现线程安全
为了修复这个问题,我们必须对 mutable 成员的访问进行同步。
使用 std::mutex
这是最通用、最常见的解决方案。我们在类中添加一个 mutable std::mutex,并在 const 函数内部使用它来保护“临界区”(critical section),也就是访问共享数据的代码块。
#include <mutex>
class Polynomial {
public:
std::vector<double> getRoots() const {
// 使用 std::lock_guard 实现 RAII 式的加锁/解锁
std::lock_guard<std::mutex> guard(m); // 构造时加锁,析构时自动解锁
// --- 进入临界区 ---
if (!rootsAreValid) {
// ... 执行昂贵的根计算 ...
rootVals = { /* ... */ };
rootsAreValid = true;
}
return rootVals;
// --- 离开临界区 (guard 析构,锁被释放) ---
}
private:
mutable std::mutex m; // 必须是 mutable
mutable bool rootsAreValid{false};
mutable std::vector<double> rootVals;
};
使用 std::atomic
对于简单的、可以被单条CPU指令修改的变量(如标志位、计数器、指针),使用 std::atomic 通常比 std::mutex 更轻量、性能更好。
让我们用一个更简单的例子来说明。假设我们想统计一个 const 函数被调用了多少次。
不安全的版本
class Counter {
public:
int getCallCount() const {
++callCount; // 数据竞争!++不是原子操作
return callCount;
}
private:
mutable int callCount{0};
};
使用 std::atomic 的安全版本:
#include <atomic>
class Counter {
public:
int getCallCount() const noexcept {
// fetch_add 是原子操作,线程安全
return callCount.fetch_add(1, std::memory_order_relaxed) + 1;
}
private:
mutable std::atomic<int> callCount{0};
};
mutable std::atomic<int>: 我们将计数器声明为std::atomic<int>。-
callCount.fetch_add(1): 这是一个原子操作,它会读取当前值,然后给它加 1,整个过程不会被其他线程中断。这比使用互斥锁的开销要小得多 std::memory_order_relaxed:“最弱的指令重排顺序,你随便优化!”。它只保证这个原子操作本身是原子的(即fetch_add不会被撕裂)。但是,它不提供任何关于其他内存操作的排序保证。编译器和 CPU 可以最大限度地对它周围的代码进行重排。
总结:
const意味着线程安全:为你的类的用户着想,你应该假设他们会在多线程环境中调用对象的const成员函数。因此,你有责任确保这些调用是安全的。- 识别共享数据:检查你的
const成员函数,找出所有被修改的mutable成员变量。这些就是需要被保护的共享数据。 - 选择正确的同步机制:
- 如果只涉及对单个变量的简单操作,优先使用
std::atomic,因为它性能更好。 - 如果需要保护一个代码块,或者修改多个相互关联的变量,使用
std::mutex(通常配合std::lock_guard或std::scoped_lock)。
- 如果只涉及对单个变量的简单操作,优先使用
mutable是同步机制的朋友:不要忘记将你的std::mutex或std::atomic成员也声明为mutable。
item17:理解特殊成员函数的生成
什么是特殊成员函数?
C++ 中有六个“特殊成员函数”,编译器可能会在需要时为你隐式地声明和定义它们:
- 默认构造函数 (Default Constructor):
Widget(); - 析构函数 (Destructor):
~Widget(); - 拷贝构造函数 (Copy Constructor):
Widget(const Widget&); - 拷贝赋值运算符 (Copy Assignment Operator):
Widget& operator=(const Widget&); - 移动构造函数 (Move Constructor) (C++11):
Widget(Widget&&); - 移动赋值运算符 (Move Assignment Operator) (C++11):
Widget& operator=(Widget&&);
Item 17 的核心就是讲解这六个函数之间“牵一发而动全身”的相互影响关系。
C++11之前
在 C++11 之前,规则相对简单,被称为“三法则”。 它指出:如果你需要显式地声明析构函数、拷贝构造函数、或拷贝赋值运算符中的任何一个,那么你几乎肯定需要同时声明所有这三个。
为什么? 因为显式声明其中之一,通常意味着你的类正在手动管理某种资源(如裸指针、文件句柄、网络套接接字等)。
- 显式析构函数:意味着你需要在对象销毁时释放资源(
delete ptr;)。 - 如果这时你依赖编译器生成的默认拷贝构造/赋值,它们只会执行浅拷贝 (shallow copy),即简单地复制指针的值。这会导致两个对象指向同一块内存,当其中一个对象被析构时,它会释放该内存,留下另一个对象的指针悬空。当第二个对象也被析构时,就会发生二次释放 (double free),导致程序崩溃。
- 因此,你必须提供自定义的拷贝操作来实现深拷贝 (deep copy),为新对象分配新的资源。
这就是三法则的精髓:手动管理资源需要一套完整的“构造-析构-拷贝”逻辑。
c++11之后
C++11 引入了移动语义,增加了两个新的特殊成员函数(移动构造和移动赋值)。更重要的是,它改变了编译器生成这些函数的规则,使其变得更加智能,也更加复杂。
核心原则:编译器认为,如果你显式声明了任何一个“资源管理”相关的函数(拷贝、移动、析构),这表明你对资源管理有特殊的意图,编译器默认生成的行为可能是不安全的。因此,它会变得“保守”,并禁用某些函数的自动生成。
规则 1:用户声明“拷贝操作”会阻止“移动操作”的生成
如果你显式声明了拷贝构造函数或拷贝赋值运算符中的任何一个:
- 编译器不会为你自动生成移动构造函数和移动赋值运算符。
理由:你已经定义了如何拷贝你的对象,这表明简单的成员逐一移动可能是不正确的。编译器不知道如何正确地“移动”你的资源,所以它选择不做,让你自己来定义。如果没有定义移动操作,那么需要移动的地方将会退回到使用拷贝操作。
规则 2:用户声明“移动操作”会阻止“拷贝操作”的生成
如果你显式声明了移动构造函数或移动赋值运算符中的任何一个:
- 编译器不会为你自动生成拷贝构造函数和拷贝赋值运算符。
理由:你已经告诉编译器“移动”和“拷贝”是不同的。这通常意味着你的类是“只移类型”(move-only),比如 std::unique_ptr。既然你已经提供了移动的特殊逻辑,那么默认的成员逐一拷贝很可能是错误的,所以编译器禁用它们。如果你还想让你的类可拷贝,你必须显式地去 = default 或自己实现它们。
规则 3:用户声明“拷贝/移动/析构”三者之一,会阻止“移动操作”的生成
如果你显式声明了以下三者中的任何一个:
- 拷贝构造函数
- 拷贝赋值运算符
- 析构函数
那么:
- 编译器不会为你自动生成移动构造函数和移动赋值运算符。
理由:这与“三法则”的逻辑一脉相承。显式声明析构函数强烈地暗示你在手动管理资源。如果一个类手动管理资源,那么编译器生成的成员逐一移动(它只会移动指针,而不会将源指针置空)几乎肯定是错误的,会导致资源的二次释放。因此,为了安全,编译器干脆不生成移动操作。同理,声明了拷贝操作也暗示了资源管理,所以也会禁用移动操作的生成。
基于上述规则,现代 C++ 的实践演变成了两个新的指导方针:
The Rule of Five (五法则)
这扩展了三法则:如果你需要显式地声明析构函数、拷贝构造、拷贝赋值、移动构造、移动赋值中的任何一个,那么你就应该审视所有这五个函数,并根据需要显式地定义、= default 或 = delete 它们。
class Widget {
public:
// ... constructor that acquires resource ...
// 1. Destructor
~Widget() { delete data; }
// 2. Copy Constructor (deep copy)
Widget(const Widget& other) : data(new int(*other.data)) {}
// 3. Copy Assignment (copy-and-swap idiom)
Widget& operator=(const Widget& other) {
// ... self-assignment check & deep copy ...
return *this;
}
// 因为我们声明了析构和拷贝操作,移动操作不会被自动生成。
// 我们必须自己提供它们!
// 4. Move Constructor
Widget(Widget&& other) noexcept : data(other.data) {
other.data = nullptr; // Crucial: leave source in a valid state
}
// 5. Move Assignment
Widget& operator=(Widget&& other) noexcept {
// ... self-assignment check ...
delete data;
data = other.data;
other.data = nullptr;
return *this;
}
private:
int* data;
};
The Rule of Zero (零法则) - 这是最佳实践!
这是现代 C++ 最推崇的理念。它指出:你应该尽量设计你的类,使得你根本不需要声明任何一个特殊成员函数。
如何做到? 通过组合。不要在你的类中使用裸指针、裸资源句柄。而是使用那些已经正确实现了五法则的资源管理类作为你的成员变量。例如:
- 用
std::unique_ptr或std::shared_ptr来管理动态分配的内存。 - 用
std::string来管理动态字符串。 - 用
std::vector来管理动态数组。
item18:对于独占资源使用std::unique_ptr
std::unique_ptr 是一个模板,它管理一个动态分配的对象。它的行为和裸指针非常相似,但提供了关键的自动内存管理。
关键特性:
- 独占所有权:在任何时刻,只有一个
unique_ptr可以指向一个给定的对象。 - 自动清理:当
unique_ptr被销毁时(例如,离开作用域),它会自动delete它所管理的对象。这利用了 RAII 机制,从根本上防止了内存泄漏。 - 轻量级:它的大小与裸指针完全相同。对它进行解引用 (
*或->) 的速度也和裸指针一样快。它是一个真正的“零成本抽象”。
为什么unique_ptr不能拷贝?
因为如果你能拷贝一个
std::unique_ptr,你会得到指向相同内容的两个std::unique_ptr,每个都认为自己拥有(并且应当最后销毁)资源,销毁时就会出现重复销毁。因此,std::unique_ptr是一种只可移动类型(move-only type)。
std::unique_ptr作为工厂函数的返回值
这是 unique_ptr 最常见和最强大的用途之一。在 C++98 中,工厂函数通常返回一个裸指针,这就把内存管理的责任抛给了调用者。调用者很容易忘记 delete,从而导致内存泄漏。
旧的、危险的方式 (返回裸指针):
class Investment { /* ... */ };
// 工厂函数
Investment* makeInvestment() {
// ... 一些逻辑 ...
return new Investment(); // 调用者必须记得 delete!
}
// 调用代码
void process() {
Investment* pInv = makeInvestment();
// ... 使用 pInv ...
// 如果在这里提前 return 或抛出异常,pInv 就泄露了!
delete pInv; // 容易忘记,且非异常安全
}
现代的、安全的方式 (返回 std::unique_ptr):
#include <memory>
class Investment { /* ... */ };
// 工厂函数返回 unique_ptr
std::unique_ptr<Investment> makeInvestment() {
// ...
return std::make_unique<Investment>();
}
// 调用代码
void process() {
auto pInv = makeInvestment(); // pInv 是 std::unique_ptr<Investment>
// ... 使用 pInv ...
// 不管函数如何退出(正常返回、提前 return、抛出异常),
// pInv 都会在离开作用域时被自动销毁,其管理的 Investment 对象也会被 delete。
// 绝对不会有内存泄漏。
}
这种模式清晰地传达了所有权的转移:makeInvestment 函数创建了资源,并将它的所有权完全转移给了调用者 process
自定义删除器
unique_ptr 的强大之处在于,它不仅仅能管理通过 new 分配的内存。通过自定义删除器 (custom deleter),它可以管理任何需要成对“获取/释放”操作的资源。
自定义删除器是一个函数或函数对象,它告诉 unique_ptr 在销毁时应该执行什么操作,而不是简单地调用 delete。
#include <cstdio>
#include <memory>
// 自定义删除器,用于关闭文件
auto fileCloser = [](FILE* fp) {
if (fp) {
fclose(fp);
std::cout << "File closed by custom deleter." << std::endl;
}
};
// 工厂函数,打开一个文件并返回一个 unique_ptr
std::unique_ptr<FILE, decltype(fileCloser)> makeFile(const char* filename, const char* mode) {
FILE* fp = fopen(filename, mode);
// 将裸指针和自定义删除器包装进 unique_ptr
return std::unique_ptr<FILE, decltype(fileCloser)>(fp, fileCloser);
}
void useFile() {
auto pFile = makeFile("my_log.txt", "w");
if (pFile) {
fputs("Hello, RAII file management!", pFile.get());
}
// useFile 函数结束时,pFile 会被销毁,
// 从而自动调用 fileCloser 来关闭文件。
}
详解std::unique_ptr<FILE, decltype(fileCloser)>
我们通常见到的 std::unique_ptr 是这样的:std::unique_ptr<MyClass>。这其实是一个简写。
std::unique_ptr 的完整模板声明看起来更像这样:
template<
class T,
class Deleter = std::default_delete<T>
> class unique_ptr;
T: 这是unique_ptr所管理的对象的类型。所以unique_ptr内部实际上持有一个T*类型的裸指针。Deleter: 这是删除器的类型。它是一个函数对象(或函数指针)的类型,unique_ptr在自己被销毁时,会调用这个Deleter来释放资源。它的默认值std::default_delete<T>只是简单地对内部指针调用delete。
当我们想要管理的资源不是通过 new 创建、不能用 delete 释放时,我们就需要提供自己的 Deleter。
在这段代码std::unique_ptr<FILE, decltype(fileCloser)>中,这里的 T 是 FILE。
FILE是 C 语言标准库(<cstdio>)中用于文件操作的结构体。- 我们从不直接创建
FILE对象,而是通过fopen()函数获取一个指向它的指针,即FILE*。 FILE*类型的资源不能用delete来释放,而必须使用配对的fclose()函数来关闭。
所以,std::unique_ptr<FILE, ...> 的意思是:“我是一个 unique_ptr,我内部持有一个 FILE* 类型的指针。”
因为不能用 delete,所以我们必须提供第二个模板参数来告诉它正确的清理方法
问题:为什么make_file()函数的返回值不用make_unique?
std::make_unique 被设计用来处理一种、且只有一种情况:在堆上分配内存并构造一个新对象。 它无法处理我们这里的场景,即接管一个已经存在的、由其他方式创建的资源,也无法附加一个自定义删除器。
std::make_unique 的设计中没有提供任何接口来让你:
- 传入一个已经存在的裸指针。
- 传入一个自定义的删除器对象。
当你需要 new 一个对象时,请使用 std::make_unique。 这是现代 C++ 的标准实践。
当你需要管理一个不是由 new 创建的资源时(比如 C API 返回的句柄、指针),请直接使用 std::unique_ptr 的构造函数,并为其提供一个自定义删除器。
unique_ptr和shared_ptr的关系
Item 18 强调 unique_ptr 是默认选择。那么什么时候才需要 shared_ptr 呢?
std::unique_ptr代表 独占所有权。它很小,很快,并且所有权模型非常清晰。std::shared_ptr代表 共享所有权。它用于“一个资源可能被多个所有者共同拥有,直到最后一个所有者消失时才被释放”的场景。它更大(通常是裸指针的两倍大小),更慢(需要原子地增减引用计数),所有权模型也更复杂(可能导致循环引用)。
最佳实践:
你应该默认使用 std::unique_ptr。只有当你发现你确实需要共享所有权时,才考虑升级到 std::shared_ptr。
一个常见的模式是:工厂函数返回 std::unique_ptr,让调用者先获得独占所有权。如果调用者后续发现需要将这个资源共享出去,它可以轻松地将 unique_ptr 转换为 shared_ptr。
auto pInvestment = makeInvestment(); // 返回 unique_ptr
// ... 一些只由我使用的代码 ...
// 现在,我需要和别人共享这个 Investment 对象了
std::shared_ptr<Investment> spInvestment = std::move(pInvestment);
// 所有权从 unique_ptr 转移给了 shared_ptr
// pInvestment 现在为空
item19:对于共享资源使用std::shared_ptr
std::shared_ptr 实现的是共享所有权 (shared ownership) 的语义。这意味着,多个 shared_ptr 实例可以同时拥有并管理同一个对象。这个被管理的对象只有在最后一个指向它的 shared_ptr 被销毁或重置时,才会被自动删除。
这解决了 unique_ptr 无法处理的一类问题:当一个资源(如一个大的数据对象、一个服务实例等)的生命周期不是由单一的代码块或对象决定,而是由多个独立的、生命周期各不相同的“客户端”共同决定时,shared_ptr 就是正确的工具。
引用计数
shared_ptr 的魔法在于引用计数 (reference counting)。
每个由 shared_ptr 管理的对象,都关联着一个控制块 (control block)。这个控制块是一个独立于被管理对象、在堆上分配的小块内存,它至少包含两样东西:
- 强引用计数 (Strong Reference Count):记录有多少个
shared_ptr正指向这个对象。这是决定对象生命周期的关键。 - 弱引用计数 (Weak Reference Count):记录有多少个
std::weak_ptr(我们稍后会讲) 指向这个对象。
shared_ptr 的生命周期管理规则:
- 当一个新的
shared_ptr通过拷贝构造或拷贝赋值指向一个对象时,强引用计数 +1。 - 当一个
shared_ptr被销毁(离开作用域)、重置或被赋予其他指针时,强引用计数 -1。 - 当强引用计数降为 0 时,
shared_ptr会自动delete它所管理的对象。 - 当弱引用计数也降为 0 时(意味着也没有
weak_ptr指向它了),控制块本身才会被释放。
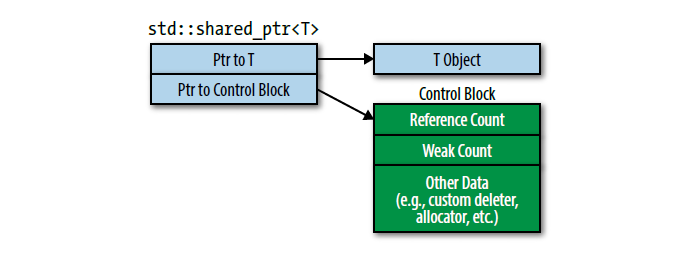
如何创建 std::shared_ptr
与 unique_ptr 类似,创建 shared_ptr 的唯一推荐方式是使用 C++11 的 std::make_shared。
#include <memory>
class Widget { /* ... */ };
// 创建一个指向 Widget 对象的 shared_ptr
auto spw = std::make_shared<Widget>();
为什么必须用 std::make_shared?
除了和 make_unique 一样能提供简洁性和异常安全之外,make_shared 还有一个极其重要的性能优势:
- 传统的创建方式:
std::shared_ptr<Widget> spw(new Widget());这会导致两次内存分配:new Widget(): 为Widget对象本身分配内存。shared_ptr的构造函数内部:为控制块分配内存。 这两次分配在内存中可能是分离的,降低了缓存效率,并且增加了分配开销。
- 使用
std::make_shared:auto spw = std::make_shared<Widget>();make_shared会执行一次单独的、更大的内存分配,这块内存足以同时容纳Widget对象和控制块。 优点:- 性能:将两次内存分配合并为一次,显著提高了效率。
- 内存局部性 (Memory Locality):对象和它的控制块在内存中是相邻的,这有助于提高 CPU 缓存的命中率。
结论:除非有极特殊的理由(比如要接管一个已经存在的裸指针),否则永远使用 std::make_shared 来创建 shared_ptr。
shared_ptr 的性能和内存开销
shared_ptr 并非免费的午餐。相比 unique_ptr,它有额外的开销:
- 大小:一个
shared_ptr对象的大小是裸指针的两倍。一个指针指向被管理的对象,另一个指针指向控制块。 - 引用计数是原子的:为了在多线程环境下安全地拷贝和销毁
shared_ptr,引用计数的增减操作必须是原子操作 (atomic operations)。原子操作通常比普通的整数操作要慢。 - 控制块的分配开销:如上所述,控制块需要额外的内存分配(除非使用
make_shared)。
因此,Item 19 强调 shared_ptr 是用于共享所有权的,这意味着你不应该因为它看起来“更强大”或“更安全”就在所有地方都使用它。如果一个资源的生命周期是清晰的、线性的,unique_ptr 是一个性能好得多的选择。
举例
想象一下,一个家庭里有多位成员,他们共同拥有一只宠物。这只宠物只有在所有家庭成员都搬走(或者不再关心它)之后,才会被送到宠物收容所。
- 宠物 (Pet) 就是我们用
shared_ptr管理的资源。 - 家庭成员 (Family Member) 就是那些
shared_ptr的实例
#include <iostream>
#include <string>
#include <memory>
// 代表我们的共享资源
class Pet {
public:
Pet(std::string name) : name_(std::move(name)) {
std::cout << "Pet '" << name_ << "' has been adopted!\n";
}
~Pet() {
std::cout << "Pet '" << name_ << "' has been sent to the shelter.\n";
}
void greet() const {
std::cout << name_ << " says Woof!\n";
}
private:
std::string name_;
};
int main() {
// 1. 爸爸领养了一只宠物。
// 我们使用 std::make_shared 来创建一个 Pet 对象,并用 shared_ptr 管理它。
std::shared_ptr<Pet> dads_ptr = std::make_shared<Pet>("Rex");
std::cout << "Rex's reference count: " << dads_ptr.use_count() << "\n"; // 引用计数为 1
dads_ptr->greet();
std::cout << "\n";
// 2. 妈妈也把这只宠物当作自己的。
// 我们通过拷贝 dads_ptr 来创建一个新的 shared_ptr。
std::shared_ptr<Pet> moms_ptr = dads_ptr;
std::cout << "Rex's reference count: " << dads_ptr.use_count() << "\n"; // 引用计数变为 2
moms_ptr->greet();
std::cout << "\n";
{
// 3. 孩子也得到了一个指向宠物的 "引用"。
// 这又创建了一个 shared_ptr,作用域限定在花括号内。
std::shared_ptr<Pet> kids_ptr = dads_ptr;
std::cout << "Rex's reference count: " << dads_ptr.use_count() << "\n"; // 引用计数变为 3
kids_ptr->greet();
std::cout << "\n";
} // 花括号结束,kids_ptr 被销毁。
std::cout << "The kid has moved out.\n";
std::cout << "Rex's reference count: " << dads_ptr.use_count() << "\n"; // 引用计数变回 2
std::cout << "\n";
// 4. 爸爸搬走了。
// 我们将他的指针重置为空。
dads_ptr.reset();
std::cout << "Dad has moved out.\n";
std::cout << "Rex's reference count: " << moms_ptr.use_count() << "\n"; // 引用计数变回 1
std::cout << "\n";
// 5. 妈妈是最后一个拥有宠物的人。
// 当妈妈的指针也消失时...
std::cout << "Mom is the last one.\n";
moms_ptr.reset();
// moms_ptr 被重置,引用计数从 1 降为 0。
// 此时,Pet 对象会自动被销毁。
std::cout << "\nNow, no one owns the pet.\n";
return 0;
}
运行结果:
Pet 'Rex' has been adopted!
Rex's reference count: 1
Rex says Woof!
Rex's reference count: 2
Rex says Woof!
Rex's reference count: 3
Rex says Woof!
The kid has moved out.
Rex's reference count: 2
Dad has moved out.
Rex's reference count: 1
Mom is the last one.
Pet 'Rex' has been sent to the shelter.
Now, no one owns the pet.
- 自动的生命周期管理:
Pet对象 “Rex” 的生命周期与shared_ptr紧密绑定。我们作为程序员,完全不需要手动调用delete。 - 引用计数 (Reference Counting):
每当一个新的
shared_ptr通过拷贝指向 “Rex” 时,引用计数use_count()就会增加。每当一个shared_ptr被销毁或重置时,引用计数就会减少。 - 共享所有权 (Shared Ownership):
爸爸、妈妈和孩子都“拥有”这只宠物。
shared_ptr完美地模拟了这种共享关系。 - 资源在最后一位所有者离开时被释放:
只有当引用计数从 1 降到 0 的那一刻(当
moms_ptr被重置时),Pet对象的析构函数~Pet()才被调用。在此之前,即使爸爸和孩子都“离开”了,宠物 “Rex” 依然安全地存在着。
这个简单的例子就是 std::shared_ptr 最核心的用途:当你有一个资源,它的生命周期不应该由某个单一的对象或函数来决定,而是应该持续存在,直到所有关心它的“人”都不再需要它为止。
item20:当std::shared_ptr可能悬空时使用std::weak_ptr
std::weak_ptr 是一种非拥有 (non-owning) 的智能指针。它的核心作用可以概括为:
- 观察者:它可以“观察”一个由
std::shared_ptr管理的对象,但不参与其生命周期管理。也就是说,weak_ptr的存在与否,不会影响对象的引用计数,也不会阻止对象被销毁。 - 安全检查器:它提供了一种安全的方式来检查所观察的对象是否仍然存在。
- 循环引用破坏者:它是打破
shared_ptr之间循环引用的标准解决方案。
可以把 weak_ptr 想象成一个持有音乐会门票票根的人。他可以通过票根知道曾经有一场音乐会,但票根本身并不能让音乐会继续进行。如果音乐会结束了(对象被销毁了),票根就失效了。
循环引用
为什么需要weak_ptr?
举例:
#include <memory>
class Child;
class Parent {
public:
std::shared_ptr<Child> child;
};
class Child {
public:
std::shared_ptr<Parent> parent; // 这里导致了循环引用
};
void createCircularReference() {
auto p = std::make_shared<Parent>();
auto c = std::make_shared<Child>();
p->child = c; // Parent 指向 Child
c->parent = p; // Child 指向 Parent
} // 函数结束,局部变量 p 和 c 被销毁
p和c被创建时,Parent和Child对象的强引用计数都为 1。p->child = c;使得Child对象的强引用计数变为 2。c->parent = p;使得Parent对象的强引用计数变为 2。createCircularReference函数结束,局部变量p和c被销毁。Parent和Child对象的强引用计数各自从 2 减为 1。- 问题来了:
Parent对象仍然被Child对象内部的shared_ptr指着,所以它的引用计数是 1。Child对象也仍然被Parent对象内部的shared_ptr指着,所以它的引用计数也是 1。 - 结果:它们的引用计数永远无法降到 0。
Parent和Child对象的析构函数永远不会被调用,导致内存泄漏
weak_ptr如何打破循环
weak_ptr 的“非拥有”特性正是解决这个问题的关键。在对象关系中,我们必须指定一方是“强”关系(拥有),另一方是“弱”关系(观察)。通常,在“整体-部分”或“父-子”关系中,让“部分”或“子”对“整体”或“父”持有弱引用。
修复后的代码:
class Parent; // 前向声明
class Child {
public:
// Child 不拥有 Parent,只是知道谁是它的 Parent
std::weak_ptr<Parent> parent; // 使用 weak_ptr!
};
class Parent {
public:
// Parent 拥有 Child
std::shared_ptr<Child> child;
};
void createHealthyReference() {
auto p = std::make_shared<Parent>();
auto c = std::make_shared<Child>();
p->child = c;
c->parent = p; // 将 shared_ptr 赋给 weak_ptr 是安全的
}
p和c被创建时,Parent和Child对象的强引用计数都为 1。p->child = c;使得Child对象的强引用计数变为 2。c->parent = p;weak_ptr不会增加Parent对象的强引用计数!Parent的强引用计数仍然是 1。(Parent的弱引用计数会 +1,但这不影响生命周期)。createHealthyReference函数结束,局部变量p和c被销毁。p被销毁,Parent对象的强引用计数从 1 降为 0。Parent对象被安全销毁!- 在
Parent的析构函数中,其成员p->child(一个指向Child的shared_ptr) 被销毁。 Child对象的强引用计数从 2 降为 1。c被销毁,Child对象的强引用计数从 1 降为 0。Child对象被安全销毁!
结论: 内存泄漏问题被完美解决。
如何使用 weak_ptr?—— lock() 是关键
你不能像 shared_ptr 或裸指针那样直接解引用 weak_ptr (* 或 ->),因为它指向的对象可能已经被销毁了。直接访问是不安全的。
weak_ptr 提供了一个核心方法 .lock() 来安全地访问对象:
weak_ptr.lock()会检查被观察的对象是否还存活。- 如果对象存活,
.lock()会返回一个指向该对象的有效的std::shared_ptr。这个返回的shared_ptr会使对象的强引用计数 +1,确保在你使用它的期间,对象不会被销毁。 - 如果对象已被销毁,
.lock()会返回一个空的std::shared_ptr。
void useChild(const Child& c) {
std::cout << "Trying to access parent from child...\n";
// 使用 .lock() 获取一个临时的 shared_ptr
if (auto shared_p = c.parent.lock()) {
// if 语句块内,shared_p 是一个有效的 shared_ptr
// Parent 对象在此期间是安全的
std::cout << "Parent exists! Accessing it.\n";
// ... 可以安全地使用 shared_p ...
} else {
// 如果 .lock() 返回空指针,说明 Parent 对象已经被销毁了
std::cout << "Parent has been destroyed.\n";
}
}
缓存
除了打破循环引用,weak_ptr 非常适合实现缓存。
场景:假设你有一个工厂,它根据 ID 从数据库加载非常大的 Widget 对象。为了避免重复加载,你想把加载过的 Widget 缓存起来。
- 如果缓存使用
std::shared_ptr<Widget>:那么只要对象在缓存中,它就永远不会被销毁,即使程序中其他所有地方都不再需要它了。这可能导致缓存无限增大,最终耗尽内存。 - 如果缓存使用
std::weak_ptr<Widget>:缓存只“观察”对象。当程序中所有对Widget的shared_ptr都消失后,Widget对象会被正常销毁。缓存中的weak_ptr随之失效。下次请求时,缓存发现weak_ptr失效了,就知道需要重新从数据库加载。
这完美地实现了“当对象仍在使用时,从缓存中快速获取;当对象不再被使用时,自动从缓存中移除”的逻辑。
item21:优先考虑使用make_unique和make_shared而非new
在现代 C++ 中,直接使用 new 来创建对象然后将其传给智能指针的构造函数,是一种过时且有风险的做法。
旧的、不推荐的方式:
auto spw = std::shared_ptr<Widget>(new Widget); // 使用 new
auto upw = std::unique_ptr<Widget>(new Widget); // 使用 new
现代的、推荐的方式:
auto spw = std::make_shared<Widget>(); // 使用 make_shared
auto upw = std::make_unique<Widget>(); // 使用 make_unique (C++14+)
下面我们来深入探讨为什么 make 函数是更好的选择。
代码简洁性与避免重复
这是最直观的好处。使用 new 的方式,你必须写两次类型名:
std::unique_ptr<std::string> pStr(new std::string("Hello"));
// ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
// 类型名写了两次
而使用 make 函数,配合 auto (Item 5),你只需要写一次:
auto pStr = std::make_unique<std::string>("Hello");
// ^^^^^^^^^^^^^
// 类型名只写一次
这不仅减少了打字量,更重要的是遵循了 “Don’t Repeat Yourself” (DRY) 原则,减少了因类型不匹配而导致错误的可能性,使代码更易于维护。
异常安全
这是 make 函数最关键、最无可辩驳的优势。直接使用 new 可能会在一些复杂的表达式中导致资源泄漏 (resource leak),而 make 函数可以完全避免这个问题。
考虑下面这个函数调用:
// 一个处理 Widget 的函数
void processWidget(std::shared_ptr<Widget> spw, int priority);
// 一个可能抛出异常的函数
int computePriority() {
// ...
if (/* some condition */) {
throw std::runtime_error("Oops!");
}
return 42;
}
现在,我们用不推荐的方式来调用 processWidget:
// 危险!可能导致内存泄漏!
processWidget(std::shared_ptr<Widget>(new Widget), computePriority());
问题出在哪里? C++ 编译器在对函数参数进行求值时,其求值顺序是不确定的。对于上面的调用,编译器可能会按照以下顺序执行:
new Widget: 在堆上成功分配了一个Widget对象,一个裸指针被创建出来。computePriority(): 编译器决定接下来调用这个函数。不幸的是,这个函数抛出了一个异常!std::shared_ptr的构造函数: 由于computePriority()抛出了异常,程序控制权立即转移到异常处理的catch块。shared_ptr的构造函数永远没有机会被调用。
结果:在第 1 步中创建的那个裸指针,本来应该被 shared_ptr接管,但现在它永远地丢失了。这块内存再也无法被释放,造成了内存泄漏。
make 函数如何解决这个问题?
现在我们用推荐的方式来调用:
// 安全!
processWidget(std::make_shared<Widget>(), computePriority());
- 情况 A:先调用
computePriority(),它抛出异常。此时make_shared根本没被调用,没有分配任何内存,一切安全。 - 情况 B:先调用
std::make_shared<Widget>()。在这个函数内部,new Widget被调用,并且立即被shared_ptr的构造函数接管。make_shared完成后,返回一个已经构造好的shared_ptr。然后computePriority()才被调用,即使它抛出异常,那个已经创建好的shared_ptr(spw) 也会在栈展开的过程中被正常析构,从而安全地释放Widget对象。
结论:make 函数将“资源分配”和“将资源交给管理者”这两个步骤绑定在了一个不可分割的操作中,从而杜绝了资源泄漏的风险。
性能提升
这个理由只适用于 std::make_shared。
我们知道 shared_ptr 需要一个控制块来存储引用计数等信息。
- 使用
std::shared_ptr<Widget>(new Widget)会导致两次内存分配:一次是new Widget为Widget对象分配内存,另一次是在shared_ptr的构造函数内部为控制块分配内存。 - 使用
std::make_shared<Widget>()只会进行一次内存分配。它会分配一块足够大的内存,同时容纳Widget对象和控制块。
make_shared 的性能优势:
- 减少分配次数:内存分配是相对昂贵的操作,将两次合并为一次可以显著提升性能。
- 提高内存局部性:对象和它的控制块在内存中是相邻的,这有助于提高 CPU 缓存的命中率,从而间接提升程序速度
无法使用make函数的例外
尽管 make 函数是压倒性的优选,但在两种罕见情况下,你可能无法使用它们:
-
需要自定义删除器 (Custom Deleters):
std::make_unique和std::make_shared都没有提供指定自定义删除器的重载版本。如果你需要管理一个需要特殊清理方式的资源(比如 C 风格的文件句柄),你必须直接使用智能指针的构造函数。auto fileCloser = [](FILE* fp){ fclose(fp); }; std::unique_ptr<FILE, decltype(fileCloser)> pFile(fopen("f.txt", "r"), fileCloser); // 这里无法使用 make_unique -
需要用花括号
{}初始化: 在 C++11 中,make函数对花括号初始化的支持不完美。虽然在 C++14/17 中情况有所改善,但在某些复杂情况下,如果你想用std::initializer_list来构造对象,直接使用new可能会更直接。// 想要创建一个包含 {1, 2, 3} 的 vector auto pVec = std::make_unique<std::vector<int>>(std::initializer_list<int>{1, 2, 3}); // C++14 可行,但啰嗦 // 或者直接用 new std::unique_ptr<std::vector<int>> pVec2(new std::vector<int>{1, 2, 3});不过,这种情况非常少见,而且通常有其他更好的设计方式。
总结与指导方针
- 默认规则:无条件地优先使用
std::make_unique和std::make_shared。 - 核心优势:它们更简洁、更安全(异常安全)、对于
shared_ptr来说性能更好。 - 例外情况:只有在你需要自定义删除器或处理一些复杂的
{}初始化时,才考虑回退到直接使用new和智能指针的构造函数。 - 关于
std::make_unique: 它是在 C++14 中才加入标准库的。如果你在使用 C++11,可以很容易地自己实现一个(书中给出了实现代码),或者直接使用std::unique_ptr<T>(new T),因为unique_ptr没有shared_ptr的性能问题,只需要注意异常安全风险即可。
item22:在使用 Pimpl 惯用法时,在实现文件中定义特殊成员函数
Pimpl 是 “Pointer to Implementation” 的缩写。它是一种 C++ 编程技巧,旨在将类的实现细节从其头文件中分离出去,从而降低编译依赖。
核心思想:
- 在类的头文件 (
.h) 中,只保留公开的接口。 - 所有私有的成员变量和私有方法都被移到一个单独的实现类(或结构体)中,通常命名为
Impl或Implementation。 - 头文件中的主类只持有一个指向这个实现类实例的私有指针。
- 所有实现类的定义都完全放在源文件 (
.cpp) 中,对外部世界完全隐藏。
主要优点:
- 编译防火墙 (Compilation Firewall):这是 Pimpl 最重要的优点。当类的私有实现发生变化时(比如增删成员变量),只有
.cpp文件需要重新编译。所有包含该类头文件的客户端代码完全不需要重新编译。对于大型项目,这可以节省大量的编译时间。 - 隐藏实现细节:你可以使用任何库、包含任何内部头文件在你的
Impl中,而不会将这些依赖暴露给类的使用者。
一个典型的、但有问题的 Pimpl 写法:
widget.h (头文件)
#include <memory>
class Widget {
public:
Widget();
// ~Widget(); // Problem: 析构函数未声明
// ... 其他接口 ...
private:
struct Impl; // 1. 只对实现类进行前向声明 (incomplete type)
std::unique_ptr<Impl> pImpl; // 2. 使用 unique_ptr 管理
};
widget.cpp (实现文件)
#include "widget.h"
// #include "gadget.h" // 假设包含一些内部实现需要的头文件
struct Widget::Impl { // 3. 在 .cpp 中完整定义实现类
// int some_data;
// Gadget g;
};
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// Widget::~Widget() = default; // Problem: 析构函数未在 .cpp 中定义
客户端代码 main.cpp:
#include "widget.h"
int main() {
Widget w;
return 0;
} // w 在这里离开作用域,它的析构函数被调用
当你尝试编译 main.cpp 时,你会得到一个编译错误!错误信息通常会提到 delete 一个不完整类型 (incomplete type) Widget::Impl。
为什么会编译失败?
- 在
main.cpp中,编译器只看到了widget.h。在widget.h中,Widget::Impl只是一个前向声明,编译器只知道“有这么一个类型”,但完全不知道它的大小、成员和析构函数。它是一个不完整类型。 - 在
main函数的末尾,Widget w被销毁。编译器需要调用~Widget()。 - 因为我们没有自己声明
~Widget(),编译器会为我们隐式生成一个默认的析构函数。这个生成的析构函数是public和inline的,它的定义被“注入”到了widget.h中。 - 这个默认的
~Widget()的函数体需要销毁Widget的所有成员,包括pImpl。 pImpl是一个std::unique_ptr<Impl>。销毁unique_ptr会调用delete来释放它所管理的Impl对象。- 关键点:
delete pImpl这个操作要求编译器知道Impl的完整定义,以便调用~Impl()并计算出需要释放的内存大小。 - 但是,在
main.cpp被编译时,编译器只看到了widget.h中的不完整类型Impl。它不知道如何销毁一个它不了解完整结构的类型,因此编译失败。
1. Pimpl 惯用法是什么?
Pimpl 是 “Pointer to Implementation” 的缩写。它是一种 C++ 编程技巧,旨在将类的实现细节从其头文件中分离出去,从而降低编译依赖。
核心思想:
- 在类的头文件 (
.h) 中,只保留公开的接口。 - 所有私有的成员变量和私有方法都被移到一个单独的实现类(或结构体)中,通常命名为
Impl或Implementation。 - 头文件中的主类只持有一个指向这个实现类实例的私有指针。
- 所有实现类的定义都完全放在源文件 (
.cpp) 中,对外部世界完全隐藏。
主要优点:
- 编译防火墙 (Compilation Firewall):这是 Pimpl 最重要的优点。当类的私有实现发生变化时(比如增删成员变量),只有
.cpp文件需要重新编译。所有包含该类头文件的客户端代码完全不需要重新编译。对于大型项目,这可以节省大量的编译时间。 - 隐藏实现细节:你可以使用任何库、包含任何内部头文件在你的
Impl中,而不会将这些依赖暴露给类的使用者。
2. 现代 Pimpl 与编译错误
在现代 C++ 中,我们自然会使用 std::unique_ptr (Item 18) 来管理这个指向实现的指针,因为它提供了自动的内存管理和独占所有权。
一个典型的、但有问题的 Pimpl 写法:
widget.h (头文件)
CPP#include <memory>
class Widget {
public:
Widget();
// ~Widget(); // Problem: 析构函数未声明
// ... 其他接口 ...
private:
struct Impl; // 1. 只对实现类进行前向声明 (incomplete type)
std::unique_ptr<Impl> pImpl; // 2. 使用 unique_ptr 管理
};
widget.cpp (实现文件)
CPP#include "widget.h"
// #include "gadget.h" // 假设包含一些内部实现需要的头文件
struct Widget::Impl { // 3. 在 .cpp 中完整定义实现类
// int some_data;
// Gadget g;
};
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// Widget::~Widget() = default; // Problem: 析构函数未在 .cpp 中定义
客户端代码 main.cpp:
CPP#include "widget.h"
int main() {
Widget w;
return 0;
} // w 在这里离开作用域,它的析构函数被调用
当你尝试编译 main.cpp 时,你会得到一个编译错误!错误信息通常会提到 delete 一个不完整类型 (incomplete type) Widget::Impl。
TEXTerror: invalid application of 'sizeof' to an incomplete type 'Widget::Impl'
note: in instantiation of member function 'std::default_delete<Widget::Impl>::operator()'
为什么会编译失败?
- 在
main.cpp中,编译器只看到了widget.h。在widget.h中,Widget::Impl只是一个前向声明,编译器只知道“有这么一个类型”,但完全不知道它的大小、成员和析构函数。它是一个不完整类型。 - 在
main函数的末尾,Widget w被销毁。编译器需要调用~Widget()。 - 因为我们没有自己声明
~Widget(),编译器会为我们隐式生成一个默认的析构函数。这个生成的析构函数是public和inline的,它的定义被“注入”到了widget.h中。 - 这个默认的
~Widget()的函数体需要销毁Widget的所有成员,包括pImpl。 pImpl是一个std::unique_ptr<Impl>。销毁unique_ptr会调用delete来释放它所管理的Impl对象。- 关键点:
delete pImpl这个操作要求编译器知道Impl的完整定义,以便调用~Impl()并计算出需要释放的内存大小。 - 但是,在
main.cpp被编译时,编译器只看到了widget.h中的不完整类型Impl。它不知道如何销毁一个它不了解完整结构的类型,因此编译失败。
3. 将特殊成员函数的定义移到实现文件
Item 22 的解决方案非常直接:强制编译器在它能看到 Impl 完整定义的地方(也就是 .cpp 文件)来生成这些特殊成员函数的代码。
如何做到?
- 在头文件 (
.h) 中声明这些函数。 - 在实现文件 (
.cpp) 中定义它们。
修正后的代码:
widget.h (头文件)
#include <memory>
class Widget {
public:
Widget();
~Widget(); // 1. 声明析构函数
// C++11 还引入了移动操作,它们也受同样问题的影响
Widget(Widget&&) = default; // 3. 声明移动操作 (可选,但推荐)
Widget& operator=(Widget&&) = default;
// ... 其他接口 ...
private:
struct Impl;
std::unique_ptr<Impl> pImpl;
};
widget.cpp (实现文件)
#include "widget.h"
struct Widget::Impl {
// ...
};
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// 2. 在 .cpp 文件中定义析构函数。
// 在这里,Widget::Impl 是一个完整类型,编译器知道如何销毁它。
Widget::~Widget() = default;
// 4. 在 .cpp 文件中定义移动操作
// Widget::Widget(Widget&&) = default; // 如果在.h中声明了,就在.cpp中定义
// Widget& Widget::operator=(Widget&&) = default;
// 注意:如果 .h 中使用了 = default, .cpp 中就不能再用了。
// 正确做法是:
// .h 中: Widget(Widget&&);
// .cpp 中: Widget::Widget(Widget&&) = default;
// (不过为了简洁,通常移动操作的声明和定义都放在 .h 中,
// 只是为了说明 Item 22 的原则,这里提一下)
// 实际上,析构函数是 Pimpl 最核心的问题。
为什么这样就解决了?
- 当编译器在
main.cpp中看到w被销毁时,它知道需要调用~Widget()。 - 因为它在
widget.h中看到了~Widget()的声明,它知道这个函数的定义在别处(在widget.cpp中)。 - 因此,编译器不会在
main.cpp中尝试生成~Widget()的代码,而是生成一个简单的函数调用指令。 - 链接器最终会在
widget.o(由widget.cpp编译而来) 中找到~Widget()的实现。 - 在
widget.cpp这个上下文中,Widget::Impl是一个完整类型。所以当编译器在这里生成~Widget()的代码时,它完全知道如何销毁pImpl,一切都合法了。
= default 的位置很重要
= default 的意思是“请编译器为我生成这个函数的默认实现”。关键在于,编译器会在你写下 = default 的那个地方生成代码。
- 写在
.h里:在所有包含头文件的地方生成内联代码(导致不完整类型问题)。 - 写在
.cpp里:只在.cpp文件中生成一个非内联的函数实现(问题解决)。
总结与指导方针
当你使用 std::unique_ptr (或其他智能指针) 实现 Pimpl 惯用法时:
- 在头文件中,对你的实现类 (
Impl) 只进行前向声明。 - 在头文件中,显式声明你的类的析构函数。
- 如果你的类需要是可移动的 (move-aware),也显式声明移动构造函数和移动赋值运算符。
- 在实现文件 (.cpp) 中提供这些已声明的特殊成员函数的定义。即使你只是想使用默认行为,也要在
.cpp文件中写下YourClass::~YourClass() = default;。
遵循这个规则,你就可以安全地将 std::unique_ptr 的强大功能与 Pimpl 惯用法的编译隔离优势完美地结合起来。
item23:理解std::move和std::forward
这是现代 C++ 中最核心、最基础,也最容易被误解的两个工具。掌握它们是理解移动语义 (move semantics) 和完美转发 (perfect forwarding) 的关键。
最重要的一点,请先记住:
std::move 和 std::forward 在运行时什么都不做。它们不会移动或转发任何东西。它们是纯粹的编译期工具,本质上都是类型转换。
std::move-无条件的右值引用转换
std::move 的作用非常简单:它无条件地将一个表达式转换为右值引用 (rvalue reference)。
它就像在对编译器说:“嘿,我向你保证,我不再关心这个对象当前的值了,你可以把它当作一个临时对象(右值)来对待,随便‘窃取’它的内部资源吧。”
它接受任何类型的参数(左值或右值),并总是返回一个右值引用。
#include <iostream>
#include <string>
#include <vector>
int main() {
std::string str = "Hello";
// str 是一个左值 (lvalue),因为它有名字,可以被取地址
// std::move(str) 的结果是一个右值引用 (std::string&&)
std::string new_str = std::move(str);
std::cout << "Original str: '" << str << "'\n";
std::cout << "New str: '" << new_str << "'\n";
}
std::move 本身不执行移动。它启用 (enables) 移动。
在上面的例子中,std::string new_str = std::move(str); 这行代码:
std::move(str)将左值str转换为右值引用。- 因为初始化的来源是一个右值引用,编译器会选择
std::string的移动构造函数string(string&&)来创建new_str。 std::string的移动构造函数会“窃取”str内部的资源(即指向 “Hello” 字符数组的指针),而不是复制整个字符串。- 移动后,
str内部的指针通常会被置为nullptr。
运行结果:
Original str: ''
New str: 'Hello'
str 的内容被“移动”到了new_str
“被移动后”的状态:
一个对象在被 std::move 之后,处于一个“有效但未指定 (valid but unspecified)” 的状态。
- 有效 (Valid):意味着你可以安全地对它执行两种操作:销毁(析构函数)和重新赋值。
- 未指定 (Unspecified):意味着你不能对其当前的值做任何假设。它可能是空的,也可能保留了某些无意义的数据。
黄金法则:在你对一个对象使用
std::move之后,除非你给它赋一个新值,否则不要再使用它。
std::forward - 有条件的右值引用转换
完美转发
std::forward 要比 std::move 复杂得多,它几乎只在一个特定的场景下使用:完美转发 (Perfect Forwarding)。
完美转发是指一个函数模板能够将其接收到的参数,以原始的值类别 (value category)(即,是左值还是右值)转发给另一个函数。
问题:值类别在传递中丢失
例:
void some_func(const std::string& s) { std::cout << "Lvalue ref called\n"; }
void some_func(std::string&& s) { std::cout << "Rvalue ref called\n"; }
template<typename T>
void wrapper(T&& arg) { // arg 是一个“转发引用”
// ...
some_func(arg); // 问题在这里!
}
int main() {
std::string s = "hi";
wrapper(s); // 期望调用左值版本
wrapper(std::string("bye")); // 期望调用右值版本
}
注意!如果直接写wrapper("bye");:
- 在
wrapper内部,我们调用some_func(arg),此时arg的类型是const char* &&。 -
const char*不能直接绑定到const std::string&或std::string&&。它需要一个隐式类型转换:从const char*构造一个临时的std::string对象。 - 编译器会生成类似这样的代码:
some_func(std::string(arg))。 std::string(arg)这个表达式的结果是一个临时的std::string对象。- 根据 C++ 的规则,临时对象是右值 (rvalue)!
运行结果:
Lvalue ref called
Lvalue ref called
T&& 的魔力:当 T 是一个需要推导的模板参数时,T&& 这种形式被称为转发引用 (Forwarding Reference)(或通用引用 Universal Reference)。它的推导规则非常特殊:
- 如果传给
wrapper的是左值(如s),T会被推导为std::string&。根据引用折叠规则 (T& && -> T&),arg的类型是std::string&。 - 如果传给
wrapper的是右值(如std::string("bye")),T会被推导为std::string。arg的类型是std::string&&。
问题来了:在 wrapper 函数内部,无论 arg 最初是左值还是右值引用,arg 本身因为有一个名字,所以它总是一个左值!
因此,some_func(arg) 总是会调用 some_func(const std::string&) 左值版本。我们丢失了原始的“右值性”。
std::forward 就是用来解决这个问题的。它是一个有条件的转换:
std::forward<T>(arg) 会检查 T 最初被推导成的类型:
- 如果
T被推导为左值引用类型(如string&),那么std::forward什么也不做,返回一个左值引用。 - 如果
T被推导为非引用类型(如string),那么std::forward会将arg转换为一个右值引用 (string&&)。
修正后:
template<typename T>
void wrapper(T&& arg) {
some_func(std::forward<T>(arg)); // 使用 std::forward
}
现在,当 wrapper(std::string("bye")) 被调用时:
T被推导为std::string。std::forward<std::string>(arg)会将左值arg转换为右值引用std::string&&。some_func(std::string&&)被正确调用
运行结果:
Lvalue ref called
Rvalue ref called
使用 std::move:
- 当你有一个左值,并且你想调用一个接受右值引用的函数(比如移动构造/赋值)。
- 当你从一个函数返回一个按值传递的、本应是局部变量的对象时(虽然现在有返回值优化 RVO,但在某些情况下
std::move仍然有用)。 - 简单说:当你确定一个对象不再需要其当前状态,想把它转移给别人时。
使用 std::forward:
- 几乎只在一种情况下使用:在一个以转发引用 (
T&&) 为参数的函数模板中,当你需要将这个参数传递给另一个函数时。 - 不要在任何其他地方使用它! 在非模板代码中错误地使用
std::forward可能会导致非常奇怪的行为
item24:区分通用引用和右值引用
在 C++11 中,&& 这个符号有两种完全不同的含义,取决于它出现的上下文:
- 右值引用 (Rvalue Reference):这是它的“普通”含义。它表示一个只能绑定到右值 (rvalue) 的引用。
- 通用引用 (Universal Reference):这是它的“特殊”含义,现在 C++ 官方标准称之为转发引用 (Forwarding Reference)。它是一种特殊的引用,既可以绑定到左值 (lvalue),也可以绑定到右值 (rvalue)。
混淆这两种引用是导致对移动语义和完美转发产生困惑的根源。Item 24 的目的就是教你如何精确地识别它们。
右值引用
右值引用就是你最常想到的 &&。它用于声明一个只能指向临时对象、std::move 的结果或其他右值的引用。
它的形式是 SomeType&&
#include <string>
void process(std::string&& s) { /* ... */ }
std::string createString() { return "temp string"; }
int main() {
std::string myStr = "hello";
process(createString()); // OK: createString() 返回一个临时对象 (右值)
process("literal"); // OK: 字符串字面量可以转换为临时的 std::string (右值)
process(std::move(myStr)); // OK: std::move 的结果是右值引用
// process(myStr); // 编译错误!myStr 是一个左值,不能绑定到右值引用
}
通用引用/转发引用
识别规则 (必须同时满足以下两个条件):
- 形式必须是
T&&:引用的类型必须是SomeTemplateParameter&&的形式。 T必须是一个需要被推导的类型:T必须是函数模板的模板参数,或者auto声明中的类型占位符。
如果这两个条件不满足,它就只是一个普通的右值引用。
例:函数模板
template<typename T>
void f(T&& param); // <-- T 是需要被推导的模板参数,形式是 T&&。
// 所以 param 是一个通用引用。
例:auto声明
auto&& var = some_expression; // <-- auto 是需要被推导的类型占位符,形式是 auto&&。
// 所以 var 是一个通用引用。
std::string myStr = "hello";
auto&& s1 = myStr; // 绑定左值
auto&& s2 = "hello2"; // 绑定右值
通用引用是如何工作的?—— 类型推导与引用折叠
通用引用的魔力在于它独特的类型推导规则,并结合了引用折叠 (reference collapsing) 规则。
类型推导规则 for T&&:
- 如果传递给通用引用的实参是一个左值,类型为
X,那么T会被推导为X&(一个左值引用)。 - 如果传递给通用引用的实参是一个右值,类型为
X,那么T会被推导为X(一个普通的类型)。
引用折叠规则 (C++11):
T& &->T&T& &&->T&T&& &->T&T&& &&->T&&(简单记:只要有&,结果就是&。只有两个&&才是&&。)
让我们把它们结合起来分析 f(T&& param):
场景 A: 传递一个左值
std::string s = "hello";
f(s); // s 是一个左值,类型是 std::string
- 类型推导:因为
s是左值,T被推导为std::string&。 - 实例化
param:param的类型是T&&,将T替换为std::string&,得到(std::string&) &&。 - 引用折叠:根据规则
T& &&->T&,param的最终类型被折叠为std::string&。 - 结果:
param变成了一个普通的左值引用,完美地绑定到了左值s上。
场景 B: 传递一个右值
f("world"); // "world" 是一个右值
- 类型推导:因为
"world"是右值,T被推导为const char*。我们为了和上面统一,用std::string右值:f(std::string("world"));。此时T被推导为std::string。 - 实例化
param:param的类型是T&&,将T替换为std::string,得到(std::string) &&。 - 引用折叠:
std::string&&不需要折叠。 - 结果:
param的类型就是std::string&&,一个右值引用,完美地绑定到了临时的std::string右值上。
结论:T&& 这个语法,通过类型推导和引用折叠的组合拳,实现了既能接收左值又能接收右值的神奇能力。
容易混淆的例子 (这些都不是通用引用!)
1. std::vector<T>&&
CPPtemplate<typename T>
void f(std::vector<T>&& param); // <-- 这是右值引用!
为什么? 它的形式不是 T&&。它是 std::vector<T>&&。T 确实需要推导,但 && 修饰的不是 T 本身,而是 std::vector<T> 这个具体的类型。
2. const T&&
CPPtemplate<typename T>
void f(const T&& param); // <-- 这是右值引用!
为什么? 它的形式不是 T&&,而是 const T&&。任何额外的 const 或 volatile 修饰都会让它失去通用性。
3. 普通成员函数
CPPclass Widget {
public:
template<typename T>
void f(T&& param); // <-- 通用引用
void g(Widget&& param); // <-- 右值引用
};
为什么? g 中的 Widget&& 是一个具体类型 Widget 的右值引用,Widget 不是需要推导的模板参数。
总结与指导方针
&&有两种含义:右值引用和通用引用(转发引用)。- 识别通用引用:它必须是
T&&的形式,并且T必须是一个正在被推导的类型(函数模板参数或auto)。 - 所有其他
&&都是右值引用:如果形式不是T&&(如std::vector<T>&&),或者T不是一个需要推导的类型 (如普通成员函数的Widget&&),那么它就是一个普通的右值引用。 - 通用引用是完美转发的基础:正是因为通用引用能够同时接收左值和右值,并保留其原始的值类别信息(通过
T的推导结果),std::forward才能利用这些信息来完成完美转发。
区分这两者是理解现代 C++ 的一个关键步骤。一旦你掌握了这个识别规则,很多关于 std::move 和 std::forward 的困惑都会迎刃而解
item25:对右值引用使用 std::move,对通用引用使用 std::forward
这个条款是 Item 23 (std::move 和 std::forward) 和 Item 24 (区分通用引用和右值引用) 的一个直接的、实践性的结论。它为你提供了一个清晰、简单、几乎在所有情况下都适用的操作指南:当你需要转发一个引用参数时,到底该用 move 还是 forward?
这个条款的核心可以概括为两条简单的规则:
- 当处理一个右值引用 (
SomeType&&) 参数时,你知道它绑定的一定是一个可以被移动的右值。当你需要将它转发给另一个函数时,你应该无条件地将其转换为一个右值,所以使用std::move。 - 当处理一个通用引用/转发引用 (
T&&) 参数时,你不知道它绑定的是左值还是右值。你需要的目标是保持其原始的值类别(左值还是右值)。std::forward正是为了这个有条件的转换而设计的,所以使用std::forward。
对右值引用使用std::move
你正在写一个 Person 类,它有一个接受右值引用的构造函数,用来从一个临时的 std::string “窃取”数据来初始化自己的成员。
#include <string>
#include <utility>
class Person {
public:
// 构造函数接受一个右值引用
explicit Person(std::string&& n)
: name(n) // <-- 这样做是错误的
{ }
private:
std::string name;
};
上面代码的问题出在哪里?
正如 Item 23 所解释的,在 Person 构造函数内部,参数 n 虽然类型是 std::string&&,但因为它有名字,所以 n 本身是一个左值!
因此,: name(n) 这行代码会调用 std::string 的拷贝构造函数来初始化 name,因为 n 是一个左值。这完全违背了我们想要移动、避免拷贝的初衷。
正确的做法是,在转发 n 之前,将它重新转换回右值。 std::move 正是为此而生
class Person {
public:
explicit Person(std::string&& n)
// name 通过移动 n 来初始化
: name(std::move(n)) // 正确!调用 std::string 的移动构造函数
{ }
private:
std::string name;
};
int main() {
std::string myName = "Scott";
// Person p(myName); // 编译错误,不能将左值绑定到右值引用
Person p(std::move(myName)); // OK,显式移动
}
对通用引用/转发引用使用 std::forward
现在,让我们看一个泛型的日志函数,它需要“完美转发”它的参数给另一个函数。
#include <iostream>
#include <utility>
#include <string>
// 真正执行日志记录的函数
void log(const std::string& msg) { std::cout << "LOG Lvalue: " << msg << std::endl; }
void log(std::string&& msg) { std::cout << "LOG Rvalue: " << msg << std::endl; }
// 一个通用的包装器,它应该完美转发参数
template<typename T>
void logWrapper(T&& msg) {
// ... 可能做一些额外的事情,比如添加时间戳 ...
// 错误的方式 1: 直接传递
// log(msg); // msg 是左值,总是调用 log(const std::string&)
// 错误的方式 2: 无脑 move
// log(std::move(msg)); // 总是调用 log(std::string&&),即使原始参数是左值!
// 正确的方式: 使用 std::forward
log(std::forward<T>(msg));
}
分析 logWrapper:
T&& msg是一个通用引用 。它可以绑定到左值或右值。- 我们的目标是:如果
logWrapper接收到一个左值,它应该调用log(const std::string&);如果它接收到一个右值,它应该调用log(std::string&&)。 std::forward<T>(msg)实现了这个有条件的转换:- 如果
msg最初绑定的是一个左值,T会被推导为std::string&。std::forward<std::string&>会返回一个左值引用。 - 如果
msg最初绑定的是一个右值,T会被推导为std::string。std::forward<std::string>会返回一个右值引用。
- 如果
- 这精确地保持了原始参数的值类别。
为什么在这里不能用 std::move?
如果你在这里用了 std::move(msg),考虑下面的调用:
std::string petName = "Darla";
logWrapper(petName); // 传入一个左值
在 logWrapper 内部,log(std::move(petName)) 会无条件地将 petName 转换为右值,导致 log(std::string&&) 被调用。这不仅是错误的(我们期望调用左值版本),而且可能还会有副作用:如果 log 函数真的移动了它的参数,那么 petName 的值在 logWrapper 调用返回后就被“掏空”了!这完全违背了调用者的意图
按值返回通用引用
如果你想按值返回一个通用引用的参数,该用 move 还是 forward?
template<typename T>
Widget makeWidget(T&& params) {
// ...
return some_expression;
}
这里的 params 是一个通用引用。假设 Widget 的构造函数接受 params。
规则:如果函数是按值返回,并且你希望利用移动语义(如果可能的话),那么你应该使用 std::move。
当你 return 一个局部变量时,编译器知道它可以被移动(NRVO/RVO 优化)。但是 params 不是一个局部变量,它是一个引用参数。编译器不知道 params 指向的对象在函数返回后是否还会被使用。
你需要显式地告诉编译器:“无论 params 最初是左值还是右值,在 return 的这一刻,我已经用完它了,你可以从中移动。”
std::move 正是这个意图的表达。
template<typename T>
T process(T&& param) {
// ... 对 param 做一些处理 ...
// 按值返回,我们确定可以从 param 移动
return std::move(param);
}
这里使用 std::move 而不是 std::forward。因为 std::forward 可能会返回一个左值引用,如果你 return 一个左值引用,可能会导致返回一个指向局部变量的悬空引用,或者触发拷贝而不是移动。而 std::move 确保了返回的是一个右值,从而优先触发移动构造函数。
| 你正在处理的引用类型是… | 你的目标是… | 你应该使用的工具是… |
|---|---|---|
右值引用 (Widget&&) |
…将它转发给另一个函数(进行移动) | std::move |
通用引用 (T&&) |
…将它以原始的值类别转发给另一个函数(完美转发) | std::forward |
通用引用 (T&&) |
…将它作为函数的返回值(按值返回) | std::move |
item26:避免在通用引用上重载
这个条款是一个非常重要的警告。它揭示了通用引用 (T&&) 在 C++ 重载决议机制中一个极其“霸道”的行为。如果你不小心,一个接受通用引用的函数模板会像黑洞一样,吸走几乎所有本应由其他重载函数处理的调用,从而导致意想不到的行为和难以发现的 bug。
一句话总结:不要写一组重载函数,其中一个版本接受通用引用,而其他版本接受“普通”类型。 那个接受通用引用的版本几乎总是会成为最佳匹配,导致你的其他重载版本永远不会被调用。
让我们用一个简单的例子来直观地感受这个问题。假设我们想写一个日志函数 log_and_add,它能记录任何类型的数据并将其添加到一个集合中。我们还想为整数类型提供一个特殊的、优化的版本。
一个看似合理的(但错误的)设计:
#include <iostream>
#include <string>
// 版本 1: 针对整数的特殊重载
void log_and_add(int idx) {
std::cout << "Calling special int version\n";
}
// 版本 2: 接受通用引用的通用模板
template<typename T>
void log_and_add(T&& name) {
std::cout << "Calling template T&& version\n";
}
int main() {
std::string petName = "Darla";
log_and_add(petName); // 1. 传入左值 std::string
log_and_add("Nemo"); // 2. 传入右值 const char*
log_and_add(22); // 3. 传入右值 int
short s = 22;
log_and_add(s); // 4. 传入左值 short
}
item27:熟悉通用引用重载的替代方法
既然直接的函数重载(一个版本是 T&&,另一个是 int)行不通,我们就需要使用其他技术来达到同样的目的。这些技术的核心思想都是,要么完全避开重载,要么以一种更可控的方式来引导编译器的类型选择。
我们再次回顾一下那个有问题的代码,它试图为一个通用日志函数提供一个针对 int 的特殊版本
// 目标:为 int 提供特殊处理,其他类型走通用模板
void log_and_add(int idx); // 特殊版本
template<typename T>
void log_and_add(T&& name); // 通用版本 (T&& 是通用引用)
// 调用
log_and_add(22); // 问题:这个调用会匹配通用模板,而不是 int 版本!
因为 T 被推导为 int,模板实例化为 void log_and_add(int&& name),这对于右值 22 来说是比 void log_and_add(int idx) 更精确的匹配,导致模板版本意外胜出。
使用不同的函数名
这是最简单、最直接、最不容易出错的方法。既然重载有问题,那我们就别用重载了。
void log_and_add_int(int idx) { /* ... */ }
template<typename T>
void log_and_add(T&& name) { /* ... */ }
// 调用时需要明确
log_and_add_int(22);
log_and_add("hello");
优点:
- 极其简单:完全没有复杂的模板技巧。
- 绝对清晰:调用哪个函数一目了然,没有歧义。
缺点:
- 破坏了接口统一性:调用者需要知道并记住有特殊版本的存在,并手动选择正确的函数名。这违背了“一个操作,一个名字”的良好接口设计原则。
标签分发
这是一种经典、强大且灵活的 C++ 技术。它的思想是,让那个“贪婪”的通用引用模板捕获所有调用,然后在函数内部,根据参数的类型特性,将工作分发给不同的、私有的实现函数。
#include <type_traits> // For std::is_integral, std::decay_t
// --- 私有实现 (通常放在匿名命名空间或作为 private 成员) ---
// 标签是 std::true_type,表示这是一个整型
template<typename T>
void log_and_add_impl(T&& name, std::true_type /* is_integral_tag */) {
std::cout << "Dispatching to int implementation\n";
// ...
}
// 标签是 std::false_type,表示这不是一个整型
template<typename T>
void log_and_add_impl(T&& name, std::false_type /* is_integral_tag */) {
std::cout << "Dispatching to general implementation\n";
// ...
}
// --- 公共接口 (唯一的入口点) ---
template<typename T>
void log_and_add(T&& name) {
// 根据 T 是否是整型,创建不同的“标签”对象 (true_type or false_type)
// 编译器会根据这个标签的类型,在编译时选择正确的 impl 重载版本
log_and_add_impl(
std::forward<T>(name),
std::is_integral<std::decay_t<T>>()
);
}
工作原理:std::is_integral<...>() 会在编译时返回一个 std::true_type 或 std::false_type 的对象。log_and_add_impl 根据这个对象的类型来进行重载。这是一种在编译时模拟 if-else 的技巧。
优点:
- 接口统一:用户只看到一个
log_and_add函数。 - 高度可扩展:你可以轻松地为其他类型(如
is_floating_point)添加新的_impl重载和标签。
缺点:
- 代码量增加:需要编写额外的
_impl函数和分发逻辑。
什么是std::true_type和std::false_type?
std::true_type 和 std::false_type 是定义在 <type_traits> 头文件中的两个极其简单的结构体。它们的作用就是在编译时表示布尔值 true 和 false。它们内部都有一个static constexpr bool value成员。
std::true_type::value的值是true。std::false_type::value的值是false。
它们是不同的类型!std::true_type 和 std::false_type 是两种完全独立的类型
什么是std::is_integral
std::is_integral 是一个类型萃取 (type trait)。它是一个模板结构体,用于在编译时判断一个给定的类型 T 是否是整型 (integral type)。
整型包括:bool, char, char16_t, char32_t, wchar_t, short, int, long, long long 及其 signed/unsigned 版本。
#include <iostream>
#include <type_traits>
int main() {
std::cout << std::boolalpha; // 让输出显示 true/false 而不是 1/0
// true
std::cout << std::is_integral<int>::value << std::endl;
std::cout << std::is_integral<const short>::value << std::endl;
std::cout << std::is_integral<bool>::value << std::endl;
// false
std::cout << std::is_integral<float>::value << std::endl;
std::cout << std::is_integral<std::string>::value << std::endl;
std::cout << std::is_integral<void*>::value << std::endl;
}
注意:在 C++17 中,有一个更方便的变量模板 std::is_integral_v<T>,它直接等价于 std::is_integral<T>::value。
std::decay是什么?
std::decay 是一个稍微复杂一些的类型萃取。它的作用是模拟“按值传参 (pass-by-value)”时发生的类型转换。它会对一个类型 T 进行一系列“清理”,得到一个“纯粹”的值类型。
std::decay<T>::type (或 C++14 的 std::decay_t<T>) 会执行以下转换:
- 移除引用:
T&->T,T&&->T。 - 移除
const和volatile限定符 (除非它指向一个const对象)。 - 转换数组和函数为指针:
T[]->T*,T(Args...)->T(*)(Args...)。
为什么需要它?
在通用引用 T&& 的上下文中,T 的推导结果可能非常复杂。例如:
- 如果传入一个
const std::string&,T会被推导为const std::string&。 - 如果传入一个
int[5]数组,T会被推导为int(&)[5](对数组的引用)。
但我们通常只想判断这个参数本质上是什么类型,而不关心它是左值引用、右值引用还是 const。
std::decay 就是用来剥去这些“外壳”,直达类型“内核”的工具。
#include <type_traits>
#include <string>
// T std::decay_t<T>
// --------------------------------------------------------
// int int
// int& int
// const int& int
// int&& int
// const int&& int
// int[5] int*
// const char* const char*
现在,我们把这三个概念组合起来,就能完全理解 Item 27 中的那行代码了:std::is_integral<std::decay_t<T>>()
它的执行流程 (在编译时):
- 假设我们调用
log_and_add(some_variable)。 - 编译器首先推导出模板参数
T的类型。假设some_variable是一个const int&,那么T就被推导为const int&。 std::decay_t<T>被应用:std::decay_t<const int&>的结果是int。- 这个结果
int被用作std::is_integral的模板参数:std::is_integral<int>。 - 因为
int是一个整型,所以std::is_integral<int>继承自std::true_type。 ()运算符在这里是创建该类型的一个临时对象。所以std::is_integral<int>()创建了一个std::true_type类型的临时对象。- 这个
std::true_type对象被作为类型标签传递给log_and_add_impl函数,从而让编译器选择了接受std::true_type的那个重载版本。
整个过程:
log_and_add(const int&)
-> T 推导为 const int&
-> std::decay_t<const int&> 得到 int
-> std::is_integral<int> 是 std::true_type
-> std::is_integral<int>() 创建了一个 std::true_type 实例
-> 调用 log_and_add_impl(..., std::true_type)
这一系列操作,共同构成了一个强大、灵活且类型安全的编译期分发机制。
std::enable_if
这种方法使用 SFINAE (Substitution Failure Is Not An Error) 规则,直接阻止通用引用模板在不应该出现的时候参与重载决议。
#include <type_traits>
// 版本 1: 针对整数的普通重载 (保持不变)
void log_and_add(int idx) {
std::cout << "Calling plain int version\n";
}
// 版本 2: 被约束的通用引用模板
template<
typename T,
// 这个模板只有在 T 不是整型时才有效
typename = std::enable_if_t<
!std::is_integral<std::decay_t<T>>::value
>
>
void log_and_add(T&& name) {
std::cout << "Calling constrained T&& version\n";
}
// 调用
log_and_add(22); // 输出: Calling plain int version
std::string s = "hi";
log_and_add(s); // 输出: Calling constrained T&& version
SFINAE 是 C++ 模板重载决议中的一条核心规则。它的意思是:
当编译器在为一个模板进行类型替换(即把具体的类型代入模板参数
T)的过程中,如果发现生成的代码是无效的、不合法的,它不会立即报错并停止编译。相反,它会“优雅地”将这个无法实例化的模板从重载候选集中移除,然后继续尝试其他的重载。
一个简单的比喻: 想象你在为一个职位招聘。你有很多份简历(模板)。
- 你拿起第一份简历(模板A),要求是“必须会开飞机”。
- 你发现应聘者(类型
int)不会开飞机(int没有fly()方法)。 - 你不会立刻打电话报警说“这里有人冒充飞行员!”(编译错误)。
- 你只会把这份简历默默地放到一边(SFINAE),然后去看下一份简历(模板B),看它是否更合适。
SFINAE 允许我们编写一些“有条件”的模板,这些模板只对满足特定条件的类型有效。
std::enable_if的工作原理
std::enable_if 是一个模板结构体,它利用了 SFINAE 规则。它的定义大致如下:
// 定义在 <type_traits>
// 通用版本 (当第一个模板参数为 false 时匹配)
template<bool B, class T = void>
struct enable_if {}; // <--- 注意:里面是空的!没有 ::type 成员
// 特化版本 (当第一个模板参数为 true 时匹配)
template<class T>
struct enable_if<true, T> {
using type = T; // <--- 只有当 B 是 true 时,才有 ::type 成员
};
它的工作机制:
- 当条件为
true时:std::enable_if<true, SomeType>会匹配到那个特化版本。它内部会有一个名为type的成员,这个type就是你传入的SomeType。 - 当条件为
false时:std::enable_if<false, SomeType>会匹配到那个通用的、空的版本。它内部没有任何名为type的成员。
例子:一个只对整型有效的函数
#include <iostream>
#include <type_traits>
#include <string>
// 这个函数模板只有在 T 是整型时才存在
template<typename T,
typename = typename std::enable_if<std::is_integral<T>::value>::type>
void process_integral(T val) {
std::cout << val << " is an integral type." << std::endl;
}
int main() {
process_integral(10); // OK
// process_integral(10.5); // 编译错误!
// process_integral("hello"); // 编译错误!
}
std::enable_if_t - 简洁的语法糖
C++14 引入了一系列 _t 后缀的类型别名来简化这种写法。std::enable_if_t 就是其中之一。
它的定义非常简单:
template<bool B, class T = void>
using enable_if_t = typename std::enable_if<B, T>::type;
它只是一个别名模板,完全等价于 typename std::enable_if<...>::type。
使用 std::enable_if_t 后的代码:
CP// 使用 C++14 的 enable_if_t,代码更简洁
template<typename T,
typename = std::enable_if_t<std::is_integral<T>::value>>
void process_integral_t(T val) {
std::cout << val << " is an integral type." << std::endl;
}
功能完全一样,但可读性大大提高。
if constexpr
C++17 的 if constexpr 是标签分发的现代化、简洁化的版本。它允许你在一个函数模板内部进行编译期的分支判断。
template<typename T>
void log_and_add(T&& name) {
if constexpr (std::is_integral_v<std::decay_t<T>>) {
// 如果 T 是整型,只有这段代码会被编译
std::cout << "Handling int inside if constexpr\n";
names.insert(std::to_string(std::forward<T>(name)));
} else {
// 否则,只有这段代码会被编译
std::cout << "Handling general type inside if constexpr\n";
names.insert(std::forward<T>(name));
}
}
- 工作原理:
if constexpr的条件在编译时求值。如果为true,else分支的代码甚至不会被实例化(就像它从未存在过一样),反之亦然。这避免了因类型不匹配(例如对std::string调用std::to_string)而导致的编译错误。 - 优点:
- 代码极其简洁:所有逻辑都在一个函数内,可读性远超标签分发和
enable_if。
- 代码极其简洁:所有逻辑都在一个函数内,可读性远超标签分发和
- 缺点:
- 需要 C++17。
Concepts(C++ 20)
C++20 的 Concepts 是解决这类问题的终极方案。它允许你用清晰、可读的语法直接约束模板。
#include <concepts>
// 版本 1: 针对整数的普通重载
void log_and_add(int idx) { /* ... */ }
// 版本 2: 使用 concept 约束的通用模板
template<typename T>
requires(!std::is_integral_v<std::decay_t<T>>) // 约束:T 不能是整型
void log_and_add(T&& name) {
/* ... */
}
- 工作原理:
requires子句直接告诉编译器这个模板的“准入规则”。当log_and_add(22)被调用时,它不满足!std::integral的约束,因此模板不参与重载决议。 - 优点:
- 无可匹敌的可读性:代码的意图一目了然。
- 极佳的错误信息:如果调用失败,编译器会给出非常清晰的关于“概念约束不满足”的错误报告。
- 缺点:
- 需要 C++20
| 方案 | 优点 | 缺点 | 适用 C++ 版本 |
|---|---|---|---|
| 不同函数名 | 最简单,无歧义 | 接口不统一,调用者负担重 | C++98 / 03 / 11+ |
| 标签分发 | 接口统一,灵活可扩展 | 代码量大,有一定模式 | C++11 / 14 |
std::enable_if |
直接在重载层面解决 | 语法丑陋,可读性差 | C++11 / 14 |
if constexpr |
非常简洁,可读性好,逻辑集中 | 需要 C++17 | C++17 |
| Concepts | 可读性最佳,意图最明确,错误信息好 | 需要 C++20 | C++20 |
item28:理解折叠引用
引用折叠规则:在 C++ 的某些特定上下文(主要是模板实例化和 auto 类型推导)中,可能会出现“引用的引用”这种语法结构。编译器不会报错,而是会根据一套简单的规则将这种“引用的引用”折叠成一个单一的引用。
规则非常简单,可以总结为一句话:
只要有左值引用 (&) 参与,结果就是左值引用。只有当所有参与者都是右值引用 (&&) 时,结果才是右值引用。
换句话说,左值引用 (&) 具有“传染性”或“压制性”。
T& &折叠成T&T& &&折叠成T&T&& &折叠成T&T&& &&折叠成T&&
你不能在普通代码里写 int& && x;,这会是编译错误。引用折叠只在几个特定的、编译器进行类型计算的场景中发生:
- 模板实例化 (Template Instantiation) - 这是最常见的场景。
auto类型推导。typedef和别名声明 (using) 的形成。decltype的使用。
我们将重点关注前两种,因为它们是理解通用引用的关键。
实例分析:引用折叠如何让通用引用工作
让我们再次回到 Item 24 的那个经典例子:一个接受通用引用的函数模板。
template<typename T>
void f(T&& param); // param 是一个通用引用
这个 T&& 的语法结合模板类型推导和引用折叠,才产生了通用引用的神奇效果。
场景 A: 传递一个左值
int x = 10;
f(x); // x 是一个 int 类型的左值
模板类型推导:
- 这是通用引用最特殊的规则:当一个左值(类型为
X)被传递给T&&时,模板参数T被推导为X&(一个左值引用)。 - 在这里,
X是int,所以T被推导为int&。
函数签名实例化 & 引用折叠:
- 编译器现在用
T = int&来替换f(T&& param)中的T。 - 它得到的中间形式是:
f( (int&) && param )。 - 编译器看到了
& &&这种“引用的引用”。 - 它应用规则 2 (
T& &&->T&)。 - 最终,函数签名被折叠成:
void f(int& param);。
结果:
- 一个接受左值引用的函数
f(int&)被成功实例化,它可以完美地绑定到我们传入的左值x。
场景 B: 传递一个右值
f(20); // 20 是一个 int 类型的右值
模板类型推导:
- 通用引用的规则:当一个右值(类型为
X)被传递给T&&时,T被推导为X(普通的、非引用的类型)。 - 在这里,
X是int,所以T被推导为int。
函数签名实例化 & 引用折叠:
- 编译器用
T = int来替换f(T&& param)中的T。 - 它得到的中间形式是:
f( (int) && param )。 - 也就是
f(int&& param)。 - 这里没有“引用的引用”,所以不需要进行折叠。
结果:
- 一个接受右值引用的函数
f(int&&)被成功实例化,它可以完美地绑定到我们传入的右值20。
auto&& 的例子
引用折叠同样适用于 auto&&:
int x = 10;
auto&& ref_x = x; // ref_x 是一个通用引用
auto 类型推导:
x是一个左值,所以auto(这里的T) 被推导为int&。
引用折叠:
- 变量的类型是
auto&&,替换后是int& &&。 - 折叠后,
ref_x的最终类型是int&。
auto&& ref_20 = 20; // 20 是右值
auto 类型推导:
20是一个右值,所以auto被推导为int。
引用折叠:
- 变量的类型是
auto&&,替换后是int&&。 - 不需要折叠,
ref_20的最终类型是int&&。
总结
- 引用折叠是 C++ 编译器在处理“引用的引用”时的一套简单规则。
- 核心规则:
&优先。只要有&,结果就是&。 - 它本身不是一个你可以直接使用的语言特性,而是模板和
auto类型推导过程中的一个底层机制。 - 正是这个机制,与通用引用的特殊类型推导规则相结合,才使得
T&&和auto&&能够同时优雅地处理左值和右值,从而为完美转发铺平了道路
item29:认识移动操作的缺点
这个标题听起来非常反直觉。C++11 引入移动语义不就是为了让我们使用它来提升性能吗?为什么 Scott Meyers 又要我们假定它不存在、不廉-价、未被使用呢?
核心思想:这个条款不是在告诉你不要使用移动语义。恰恰相反,它是在教你如何编写健壮的、通用的代码。它是一个思维模型,提醒你在编写泛型代码或处理不确定类型时,不能理所当然地认为移动操作总是可用且高效的。你的代码应该在移动操作可用时受益,但在其不可用或不廉价时,也必须能够正确地工作(通常是通过回退到拷贝操作)。
假定移动操作不存在
为什么移动操作可能不存在?
一个类型 T 可能根本就没有移动操作(移动构造函数和移动赋值运算符)。
最常见的原因是 Item 17 中描述的规则:如果一个类显式声明了拷贝操作、或拷贝赋值、或析构函数中的任何一个,编译器将不会为它自动生成移动操作。
#include <iostream>
#include <utility>
#include <string>
class ResourceHog {
public:
ResourceHog() { std::cout << "Resource acquired\n"; }
~ResourceHog() { std::cout << "Resource released\n"; } // <--- 显式声明了析构函数
// 编译器会生成拷贝构造函数
ResourceHog(const ResourceHog&) { std::cout << "Resource copied\n"; }
// 编译器会生成拷贝赋值运算符
ResourceHog& operator=(const ResourceHog&) { std::cout << "Resource copy-assigned\n"; return *this; }
// 由于声明了析构函数,编译器“不会”生成移动操作!
// ResourceHog(ResourceHog&&) = delete; // 效果上如此
// ResourceHog& operator=(ResourceHog&&) = delete; // 效果上如此
};
int main() {
ResourceHog r1;
std::cout << "Trying to move r1...\n";
ResourceHog r2 = std::move(r1); // 我们“请求”移动 r1
}
运行结果:
Resource acquired
Trying to move r1...
Resource copied
Resource released
Resource released
发生了什么?
- 我们对
r1使用了std::move,这将其转换为了一个右值引用,发出了一个强烈的“请移动我”的信号。 - 编译器尝试为
r2寻找ResourceHog的移动构造函数。 - 它发现
ResourceHog没有移动构造函数(因为它被隐式删除了)。 - 根据 C++ 的重载决议规则,它会回退 (fallback) 去寻找一个可以接受右值的构造函数。
const ResourceHog&(拷贝构造函数的参数) 可以绑定到一个右值。 - 因此,拷贝构造函数被调用了。
启示:即使你写了 std::move,也不能保证移动真的会发生。如果类型不支持移动,它会悄无声息地变成一次拷贝。你的代码必须能够在这种情况下正确工作。
假定移动操作不廉价
我们常常有一个误解:移动操作就是简单地交换几个指针,开销接近于零。
在很多情况下这是对的,但并非总是如此。
例子 1:std::array
std::array<T, N> 的数据是直接存储在对象内部的,而不是在堆上。
std::array<int, 1000000> a1;
// ...
auto a2 = std::move(a1); // 这会移动一百万个整数!
例子 2:std::string 和小字符串优化 (SSO)
很多 std::string 的实现都包含小字符串优化。如果字符串很短(比如少于 15 个字符),它的内容会直接存储在 string 对象内部的缓冲区里,以避免堆分配。
- 当字符串很长时:移动一个
std::string确实是廉价的,只需交换内部的指针、大小和容量三个成员。 - 当字符串很短 (触发 SSO) 时:移动一个
std::string就和拷贝它一样,需要将缓冲区的内容逐字节复制到新对象中。
启示:一个移动操作的成本可能取决于对象的状态(比如字符串的长度)或者类型(比如 std::array)。你不能假设它总是廉价的。
假定移动操作未被使用
即使一个类型的移动操作存在且廉价,编译器也可能不会使用它。
原因 1:编译器无法保证安全性(异常安全)
这是 Item 14 (noexcept) 的核心。标准库中的很多组件(特别是容器)为了提供强异常安全保证 (strong exception guarantee),在某些情况下会拒绝使用可能会抛出异常的移动操作。
最经典的例子就是 std::vector 扩容:
std::vector<MyType> vec;
// ... vec 满了,需要扩容 ...
vector 需要将旧内存中的元素移动到新内存中。
- 如果
MyType的移动构造函数被标记为noexcept,vector会放心地使用它。 - 如果
MyType的移动构造函数没有被标记为noexcept,vector会认为它可能抛出异常。如果在移动第 N 个元素时抛异常,vector将处于一种“半移动”的损坏状态,无法回滚。为了保证强异常安全,vector会拒绝使用这个移动构造函数,转而使用拷贝构造函数(如果拷贝时抛异常,原始数据依然完好无损)。
启示:即使你提供了移动操作,如果没把它标记为 noexcept,在一些关键的性能场景下,它也可能不会被使用。
原因 2:编译器执行了更强的优化(拷贝/移动省略) 在某些情况下,编译器非常聪明,它会发现连移动都是多余的,可以直接在目标内存上构造对象。这被称为拷贝省略 (copy elision) 或 移动省略 (move elision),其中最著名的是返回值优化 (RVO/NRVO)。
Widget makeWidget() {
Widget w;
// ...
return w; // 理论上会移动 w 来创建返回值
}
Widget w_main = makeWidget(); // 理论上会移动返回值来构造 w_main
在实践中,现代编译器会直接在 w_main 的内存位置上构造 makeWidget 函数内部的 w。整个过程中,没有拷贝,也没有移动。析构函数只会被调用一次。
启示:你不能依赖移动操作一定会被调用。例如,你不能在移动构造函数中放置一些必须执行的逻辑(比如更新一个全局计数器),因为它可能根本不会被执行。
总结与指导方针
这个条款的真正目的是让你在编写泛型代码时保持一种审慎和务实的态度。
- 为最坏情况设计:你的代码逻辑不应该依赖于移动操作的可用性或性能。它应该在只有拷贝可用的情况下也能正确工作。
- 拥抱最好情况:同时,你的代码应该能够利用移动语义。通过正确使用
std::move和完美转发,当移动可用时,你的代码会自动获得性能提升。 noexcept是关键:如果你编写的移动操作确实不会抛出异常,一定要将它们标记为noexcept。这是向编译器和标准库做出承诺,允许它们在关键路径上使用你的移动操作。
所以,这个条款的智慧在于:“在设计时要保守(假定只有拷贝),但在实现时要进取(正确使用 std::move 和 noexcept 来启用移动)。
item30:熟悉完美转发失败的情况
虽然完美转发是一个极其强大的工具,但它并非万能。在某些特定情况下,它会“失败”——这里的“失败”通常不是指编译错误,而是指它无法将参数以其原始的形式和值类别完美地转发出去,或者推导出的类型与我们直觉上的预期不符。
理解这些失败案例,可以帮助我们避免一些非常隐蔽的 bug,并知道何时不能完全依赖完美转发。
完美转发依赖于从函数调用中为函数模板推导出的类型 T。但有些表达式的类型信息,是无法通过这个机制来完美传递的。
Item 30 指出了几种主要的失败情况。
花括号初始化列表
这是最常见也是最经典的失败案例。
问题:一个花括号初始化列表,如 {1, 2, 3},它本身没有类型 (has no type)。
编译器通常可以根据上下文推断出它应该是什么类型(比如 std::vector<int> 或 std::initializer_list<int>)。但是,在模板类型推导中,这个机制失效了。
#include <vector>
void f(const std::vector<int>& v) {}
template<typename T>
void fwd(T&& param) {
f(std::forward<T>(param));
}
int main() {
std::vector<int> v = {1, 2, 3};
fwd(v); // OK: T 推导为 std::vector<int>&
// fwd({1, 2, 3}); // 编译错误!
}
为什么 fwd({1, 2, 3}) 会失败?
- 编译器看到
{1, 2, 3},它需要为fwd的模板参数T推导出一个类型。 - 但是
{1, 2, 3}本身没有一个确定的类型。它是一个“待定”的东西。 - 编译器无法为
T推导出任何类型,因此模板推导失败,导致编译错误。
错误信息通常是:"could not deduce template argument for 'T' from '{1, 2, 3}'"。
解决方案:
要解决这个问题,你必须在调用点帮助编译器,明确地告诉它 {...} 应该是什么类型。
// 解决方案 A: 使用 auto
auto il = {1, 2, 3}; // il 的类型被推导为 std::initializer_list<int>
fwd(il);
// 解决方案 B: 显式类型转换
fwd(std::vector<int>{1, 2, 3});
0或NULL作为空指针
在 C++11 之前,0 和 NULL 被用作空指针常量。但它们的实际类型是整型 (int 或 long)。
问题:完美转发会忠实地转发它们的整型本质,而不是它们的“空指针”意图。
#include <iostream>
void f(int i) { std::cout << "f(int)\n"; }
void f(void* p) { std::cout << "f(void*)\n"; }
template<typename T>
void fwd(T&& param) {
f(std::forward<T>(param));
}
int main() {
f(0); // 调用 f(int)
f(NULL); // 在大多数实现中,也调用 f(int)
// fwd(0); // 通过 fwd 调用,T 推导为 int,调用 f(int)
// fwd(NULL); // 通过 fwd 调用,T 推导为 long 或 int,调用 f(int)
}
如果你本意是想通过 fwd 来调用 f(void*) 的指针版本,完美转发失败了。它无法理解 0 在这个上下文中的特殊含义。
解决方案:使用 nullptr (Item 8)。nullptr 的类型是 std::nullptr_t,它可以被明确地推导和转发,并能正确地转换为各种指针类型。
f(nullptr); // 调用 f(void*)
fwd(nullptr); // T 推导为 std::nullptr_t,正确调用 f(void*)
仅有声明的整形static const成员
问题:在 C++17 之前,一个在类内部初始化的 static const 整型成员,如果只在类内声明而没有在 .cpp 文件中定义,你不能取它的地址。完美转发有时需要通过引用传递参数,这在底层可能涉及到取地址的操作。
class Widget {
public:
static const std::size_t MinVals = 28; // 只有声明
};
// const std::size_t Widget::MinVals; // .cpp 文件中的定义被省略了
template<typename T>
void fwd(T&& param) { /* ... */ }
int main() {
fwd(Widget::MinVals); // 可能会导致链接错误!
}
当 fwd 尝试通过引用 const std::size_t& 来绑定 Widget::MinVals 时,链接器可能需要这个变量的地址,但因为它没有在 .cpp 文件中被定义,所以找不到,导致链接失败。
解决方案:
- 传统方式:在
.cpp文件中提供定义:const std::size_t Widget::MinVals;。 - 现代方式 (C++17+):使用
inline变量:static inline constexpr std::size_t MinVals = 28;。这使得它不需要在类外定义。
class Widget {
public:
static inline const std::size_t MinVals = 28; // 这样就没有链接错误了
};
template<typename T>
void fwd(T&& param) { /* ... */ }
int main() {
fwd(Widget::MinVals); // 可能会导致链接错误!
}
重载的函数名和模板名
问题:当你直接传递一个重载函数的名字或一个函数模板的名字时,编译器无法确定你指的是哪一个具体版本。
void f(int);
void f(double);
template<typename T>
void fwd(T&& param) { /* ... */ }
// fwd(f); // 编译错误!是 f(int) 还是 f(double)?
完美转发无法解决这种歧义。
解决方案:你必须在调用点通过显式指定类型或类型转换来消除歧义。
// 解决方案 A: 使用函数指针并指定类型
using FuncPtr = void(*)(int);
FuncPtr fp = f;
fwd(fp);
// 解决方案 B: 使用 static_cast
fwd(static_cast<void(*)(int)>(f));
位域 (Bitfields)
问题:位域不是独立的内存对象,你不能直接创建一个指向位域的指针或非 const 引用。完美转发的机制依赖于传递引用,而这对于位域是做不到的。
struct S {
uint32_t a : 1; // a 是一个 1-bit 的位域
};
template<typename T>
void fwd(T&& param) { /* ... */ }
S s;
// fwd(s.a); // 编译错误!
编译器会先从位域中读取值,创建一个临时的、普通类型的变量(比如 int),然后把这个临时变量(右值) 传递给 fwd。你丢失了“这是一个位域”的信息,而且无法通过引用修改它。
解决方案:没有通用的解决方案。如果你需要处理位域,通常需要编写专门的代码。你可以传递一个 lambda,在 lambda 内部操作位域。
总结与指导方针
完美转发是一个强大的工具,但它不是魔法。它转发的是编译器在调用点能够推导出的类型信息。
当以下情况出现时,完美转发会“失败”:
- 无法推导出类型:花括号初始化列表
{...}。 - 推导出的类型不符合你的意图:
0或NULL被推导为整型,而不是空指针。 - 引用/指针的限制:位域不能被直接引用;仅声明的
static const成员可能没有地址。 - 存在歧义:重载的函数名或模板名。
当你编写接受通用引用的函数模板时,要意识到这些限制。如果你的函数需要处理这些特殊情况,你可能需要提供文档说明,或者提供额外的重载(使用 Item 27 的技术,如标签分发)来专门处理它们。
item31:避免使用默认捕获模式
默认捕获模式 [=] 和 [&] 是危险的,应该优先使用显式捕获。
[&]的危险:容易导致悬空引用 (dangling references),特别是当 Lambda 的生命周期超过其引用的局部变量时。[=]的危险:看似安全,但它通过复制指针(而不是指针指向的内容)和复制this指针来捕获,这两种情况都可能导致悬空指针。
除了悬空引用,默认捕获模式还存在其他问题,进一步证明了我们应该避免使用它们。
默认捕获无法捕获“只能移动”的类型
在 C++11 中,如果你想将一个只能移动 (move-only) 的类型(如 std::unique_ptr)的所有权移入一个 Lambda,默认捕获模式完全无能为力。
#include <memory>
void func() {
auto pWidget = std::make_unique<Widget>();
// 目的:创建一个 lambda,接管 pWidget 的所有权
// auto lambda = [=]() { /* use *pWidget */ }; // 编译错误!
// [=] 尝试“按值”捕获,即拷贝 pWidget。
// 但 std::unique_ptr 是不可拷贝的。
// auto lambda2 = [&]() { /* use *pWidget */ }; // 合法,但非常危险!
// [&] 捕获 pWidget 的引用。当 func 结束时,pWidget 被销毁,
// lambda 内部的引用就悬空了。
}
在 C++11 中,要解决这个问题,需要使用一些复杂的技巧,比如将 unique_ptr 包装在 std::shared_ptr 中,或者使用 std::bind。这些方法都很笨拙。
解决方案:C++14 广义 Lambda 捕获 (Generalized Lambda Capture)
C++14 的广义 Lambda 捕获完美地解决了这个问题。它允许你在捕获列表中声明并初始化一个新的变量,这个新变量只存在于 Lambda 内部。
语法:[new_var = expression]
解决 unique_ptr 的移动问题:
// C++14 or later
void func_cpp14() {
auto pWidget = std::make_unique<Widget>();
// 使用广义捕获,显式地移动 pWidget
auto lambda = [pW = std::move(pWidget)]() {
// ... 现在可以安全地使用 pW ...
};
// pWidget 在这里已经是 nullptr,所有权已经转移给了 lambda
}
[pW = std::move(pWidget)]:
- 在捕获列表中,我们声明了一个新的变量
pW,它只属于这个 Lambda。 pW通过移动pWidget来初始化。- 这正是我们想要的:将
unique_ptr的所有权安全地转移到 Lambda 内部。
这个特性极大地增强了 Lambda 的能力,使得默认捕获模式更加相形见绌。
指针悬空问题
class Widget {
public:
void doWork() {
// [=] 隐式捕获了 this 指针,非常危险
auto func = [=] { /* ... use member_ ... */ };
}
private:
int member_;
};
如果 Widget 对象在 func 被调用前销毁,func 内部的 this 指针就悬空了。
C++14 解决方案:复制你需要的成员
广义捕获允许我们只复制我们需要的成员,而不是依赖于 this 指针。
// C++14 Solution
class Widget_cpp14 {
public:
void doWork() {
// 只复制 member_,完全不捕获 this 指针
auto func = [val = member_] {
// ... 现在使用 val ...
// 这个 lambda 与 Widget 对象完全解耦
};
}
private:
int member_;
};
[val = member_]:在 Lambda 内部创建了一个名为val的新变量,它是member_的一个副本。- 这个 Lambda 的生命周期与
Widget对象的生命周期完全无关,绝对安全。
C++17 的补充方案:捕获 *this
C++17 增加了一个更直接的语法,如果你确实需要整个对象的副本(而不是单个成员)。
// C++17 Solution
class Widget_cpp17 {
public:
void doWork() {
// [*this] 明确地在 lambda 内部创建了 Widget 对象的一个副本
auto func = [*this] {
// ... 现在可以直接使用 member_ ...
// 这里的 member_ 是 lambda 内部副本的成员
};
}
private:
int member_;
};
[*this] 是 [self = *this] 这种广义捕获的一个语法糖,意图更明确。
item32:使用初始化捕获来移动对象到闭包中
这个条款是 C++14 中 Lambda 表达式最重要的增强之一。它解决了一个在 C++11 中非常棘手的问题:如何安全、高效地将一个只能移动 (move-only) 的对象(如 std::unique_ptr)的所有权转移给一个 Lambda。
这个特性在官方标准中被称为广义 Lambda 捕获 (Generalized Lambda Capture),而 “初始化捕获 (init capture)” 是它最常见、最强大的用法之一。
核心思想
在 C++11 中,Lambda 的捕获列表只能通过简单的“按值” (=) 或“按引用” (&) 来捕获已经存在的变量。这对于只能移动、不能拷贝的类型来说,是一个巨大的限制。
C++14 的初始化捕获引入了一种全新的语法:[ new_variable = expression ]。它允许你在捕获列表中声明并初始化一个全新的变量,这个新变量只存在于 Lambda 的闭包(closure,即编译器为 Lambda 生成的那个匿名对象)内部。
这个简单的语法解锁了强大的能力,特别是移动捕获。
C++11的局限
让我们用一个 std::unique_ptr 的例子来展示 C++11 的困境。std::unique_ptr 是一个典型的只能移动、不能拷贝的类型。
目标:创建一个 Lambda,让它接管一个 std::unique_ptr 的所有权,以便在稍后的某个时间点(比如在另一个线程中)安全地使用它。
#include <memory>
#include <iostream>
class Widget { /* ... */ };
void analyzeWidget(const Widget& w) { /* ... */ }
void cpp11_approach() {
auto pWidget = std::make_unique<Widget>();
// ... 对 pWidget 做一些事 ...
// 现在,想创建一个 lambda 来使用 pWidget
// 尝试 1: 按值捕获 [=]
// auto func = [=] { analyzeWidget(*pWidget); };
// 编译错误!
// [=] 尝试拷贝 pWidget,但 std::unique_ptr 是不可拷贝的。
// 尝试 2: 按引用捕获 [&]
// auto func = [&] { analyzeWidget(*pWidget); };
// 编译通过,但极其危险!
// func 捕获了 pWidget 的引用。当 cpp11_approach 函数返回时,
// 局部的 pWidget 被销毁,func 内部的引用就变成了悬空引用!
}
C++14的解决方案
C++14 的初始化捕获用一种非常优雅的方式解决了这个问题。
语法:[ new_var = std::move(old_var) ]
// C++14 or later
void cpp14_solution() {
auto pWidget = std::make_unique<Widget>();
// ...
// 使用初始化捕获,完美解决问题
auto func = [pW = std::move(pWidget)]() {
// 在这里,pW 是 lambda 的一个成员变量
// 它通过移动 pWidget 初始化
analyzeWidget(*pW);
};
// 调用 func
func();
// 此时,原始的 pWidget 已经是 nullptr,
// 因为它的所有权已经被“移动”到了 lambda 内部的 pW 中。
// assert(pWidget == nullptr);
}
初始化捕获的其他强大用途
你可以捕获一个表达式的结果,而不是变量本身。这对于预计算和简化 Lambda 内部逻辑非常有用。
#include <vector>
std::vector<double> data = {1.5, 2.5, 3.5};
// 捕获 data 的大小,而不是对整个 vector 的引用
auto func = [size = data.size()]() {
std::cout << "Data size was: " << size << std::endl;
};
data.push_back(4.5); // 修改原始 data
func(); // 输出: Data size was: 3
func 只捕获了 data.size() 在 Lambda 创建时的那个值 (3),它与 data 本身完全解耦。
解决 this 指针捕获问题
初始化捕获是解决 Item 31 中 [=] 隐式捕获 this 指针导致悬空问题的完美方案。
class Widget {
public:
void doWork() {
// ...
// [=] 会隐式捕-获 this 指针,危险
// C++14 初始化捕获方案:只复制你需要的成员
auto func = [divisor_copy = this->divisor]() {
// ... 使用 divisor_copy ...
// 这个 lambda 与 Widget 对象的生命周期完全无关
};
}
private:
int divisor;
};
这个 Lambda 创建了一个名为 divisor_copy 的成员,它是 this->divisor 的一个副本。它根本不依赖 this 指针,因此绝对不会悬空。
- 当你想把一个只能移动的对象(如
std::unique_ptr)的所有权转移给一个 Lambda 时,初始化捕获是 C++14 及以后唯一的正确选择。 - 当你想让 Lambda 与外部对象(特别是
this)解耦时,通过初始化捕获来复制你需要的成员,而不是捕获整个this指针。 - 初始化捕获是一种更强大、更明确、更安全的捕获机制。当你发现简单的按值/按引用捕获无法满足需求时,就应该想到它。
这个特性是 C++14 中对 Lambda 最重要的改进,它使得 Lambda 在资源管理和异步编程等领域的应用变得更加健壮和灵活
item33:对 auto&& 参数使用 decltype 来 std::forward 它们
我们已经知道 (Item 25),在函数模板中完美转发一个通用引用 (T&&) 的标准写法是 std::forward<T>(param)。
// 普通函数模板
template<typename T>
void f(T&& param) {
// ...
some_func(std::forward<T>(param)); // 使用 T
}
问题来了:在 C++14 的泛型 Lambda 中,参数是 auto&&,这里没有一个名为 T 的模板参数让你传递给 std::forward!
// 泛型 Lambda
auto f = [](auto&& param) {
// ...
// std::forward<???>(param) <-- ??? 应该是什么?
some_func(std::forward<???>(param));
};
Item 33 的核心就是告诉你,在这种情况下,??? 的正确写法是 decltype(param)。
decltype 是一个在编译时推导表达式类型的操作符。它在这里的作用,是精确地恢复出我们需要的那个不可见的 T 的类型信息,以便 std::forward 能够正确工作。
decltype(param) 的推导规则与 auto 有一点关键的不同,这正是我们需要的:
- 如果表达式是一个左值引用
X&,decltype的结果就是X&。 - 如果表达式是一个右值引用
X&&,decltype的结果就是X&&。
这正好与通用引用 (T&&) 的类型推导规则完美配合!
#include <iostream>
#include <utility>
#include <string>
void some_func(const std::string& s) { std::cout << "Lvalue ref called\n"; }
void some_func(std::string&& s) { std::cout << "Rvalue ref called\n"; }
int main() {
// 正确实现完美转发的泛型 Lambda
auto f = [](auto&& param) {
// 对 auto&& 参数 param, 使用 decltype(param) 来转发
some_func(std::forward<decltype(param)>(param));
};
std::string s = "hello";
std::cout << "Passing lvalue:\n";
f(s); // 调用 f,param 是 std::string&, decltype(param) 是 std::string&
// std::forward<std::string&> 返回左值引用
std::cout << "Passing rvalue:\n";
f("world"); // 调用 f,param 是 const char*&&
// (经过类型转换后)param 是 std::string&&, decltype(param) 是 std::string&&
// std::forward<std::string&&> 返回右值引用
}
总结与指导方针
这个条款虽然技术性很强,但它的最终结论非常简单和明确:
-
在普通函数模板中,完美转发一个通用引用
T&& param的写法是:std::forward<T>(param) -
在 C++14 泛型 Lambda 中,完美转发一个通用引用
auto&& param的写法是:std::forward<decltype(param)>(param)
这个区别是由于泛型 Lambda 语法的便利性所带来的一个必然结果——它隐藏了底层的模板参数 T。decltype 只是我们用来“找回”这个被隐藏的类型信息的一种巧妙方式。
记住这个模式,你就可以在泛型 Lambda 中自如地使用完美转发,编写出高度通用和高效的代码。
item34:优先考虑lambda而非std::bind
std::bind 的主要功能是将一个可调用对象(函数、函数对象等)与一组参数绑定在一起,生成一个新的、参数更少的可调用对象。它可以重新排列参数、忽略某些参数、或者将占位符 (_1, _2…) 替换为未来调用时提供的参数。
虽然功能强大,但 std::bind 存在几个固有的缺点,而 Lambda 在这些方面都表现得更出色。
可读性差
我们有一个函数,它需要一个 bool(int) 形式的可调用对象。我们想用一个 Widget 类的成员函数 bool isLucky(int, int) 来适配它,其中第二个参数我们想固定为 7。
#include <functional>
struct Widget {
bool isLucky(int val, int magicNum) const { return val % magicNum == 0; }
};
// ...
using namespace std::placeholders; // for _1, _2, etc.
Widget w;
auto f = std::bind(&Widget::isLucky, w, _1, 7); // <-- 这是什么意思?
解读 std::bind 这行代码需要费一番脑筋:
-
&Widget::isLucky:我们要绑定的是Widget::isLucky这个成员函数。 -
w:这是第一个参数。因为isLucky是一个成员函数,它的第一个“隐式”参数是this指针。std::bind需要一个对象实例(w)来充当this。注意这里是按值拷贝了w! -
_1:这是一个占位符,意思是“把将来调用f时提供的第一个参数放在这里”。 -
7:这是一个被绑定的值,它将作为isLucky的第二个参数。
使用 Lambda 的等价实现:
Widget w;
auto f_lambda = [w](int val) { return w.isLucky(val, 7); }; // <-- 清晰直观!
Lambda 的版本读起来就像普通的函数调用,意图一目了然:“创建一个函数,它接受一个 val,然后用一个捕获的 w 的副本调用 w.isLucky,第二个参数固定为 7”。
难以调试
std::bind 生成的函数对象的类型非常复杂,由编译器在内部生成,通常是一长串难以辨认的模板名。当编译出错时,错误信息往往非常冗长且难以理解。
而 Lambda 的代码就在你眼前,如果内部调用出错,错误信息会直接指向 Lambda 体内的那一行,调试起来要容易得多
对重载不友好
std::bind 无法直接处理重载函数。你必须手动选择一个特定的重载版本。
void myFunc(int);
void myFunc(double);
// auto f = std::bind(myFunc, _1); // 编译错误!是哪个 myFunc?
// 必须手动转换来消除歧义
auto f = std::bind(static_cast<void(*)(int)>(myFunc), _1);
Lambda 可以自然地处理重载,因为它在内部的调用会触发常规的重载决议。
auto f_lambda = [](auto val) { myFunc(val); }; // C++14 泛型 lambda
f_lambda(10); // 调用 myFunc(int)
f_lambda(3.14); // 调用 myFunc(double)
可能导致意外的性能开销
std::bind 通常是通过类型擦除(type erasure)和复杂的内部结构来实现的,这可能导致编译器难以对其进行内联(inlining)等优化。
而 Lambda 生成的闭包对象是一个简单的、编译器完全可见的 struct,编译器非常擅长优化它,经常可以将其完全内联,从而生成与手写代码一样高效的机器码。
std::bind 对参数的绑定方式(值、引用、cref)也比 Lambda 捕获更复杂,更容易出错。例如,上面 std::bind(&Widget::isLucky, w, ...) 按值拷贝了 w,如果你想按引用传递,需要写成 std::bind(..., std::ref(w), ...)。而 Lambda 的 [w] 和 [&w] 意图非常清晰
总结与指导方针
- Lambda 优先:在 C++11 及以后的代码中,当你需要一个函数适配器时,首先考虑使用 Lambda。
- 可读性:Lambda 的代码更清晰、更直观,更容易理解和维护。
- 灵活性:Lambda 可以轻松处理重载,并且泛型 Lambda 提供了
std::bind无法比拟的泛型能力。 - 性能:Lambda 通常能被编译器更好地优化,生成更高效的代码。
std::bind已过时:对于新的代码,几乎没有理由再使用std::bind。你应该只在维护需要它的旧代码库时才去接触它。
这个条款是现代 C++ 演进的一个缩影:语言核心特性(如 Lambda)的不断增强,使得一些原有的、更复杂的库工具(如 std::bind)逐渐变得不再必要。拥抱 Lambda,会让你的 C++ 代码更现代化、更简洁、也更高效。
item35:优先使用基于任务的编程,而非基于线程的编程
这个条款是现代 C++ 并发编程的一个核心指导思想。它主张我们应该从更高层次、更抽象的角度来思考并发,而不是直接去操作底层的 std::thread 对象。这不仅能让代码更简洁、更安全,还能获得更好的性能和可组合性。
基于线程的编程 (Thread-Based Programming),以 std::thread 为代表,是一种低层次的并发模型。
- 你负责管理一切:你必须手动创建线程,确保它们在正确的时间启动,处理线程的
join或detach,手动传递数据,并自己处理线程间的同步和异常。 - 关注点是“如何做”:你的代码充满了线程管理的细节,而不是你真正想解决的业务问题。
- 就像使用汇编语言:功能强大,但极其繁琐且极易出错。
基于任务的编程 (Task-Based Programming),以 std::async, std::packaged_task, std::future 和 std::promise 为代表,是一种高层次的并发模型。
- 你只描述“做什么”:你定义一个“任务”(一个可调用对象),然后把它交给 C++ 并发库去执行。
- 运行时为你管理:C++ 标准库的线程池 (thread pool)(虽然标准没有明说,但这是事实上的实现方式)会负责调度线程、分配任务、管理硬件资源。
- 关注点是“做什么”:你的代码描述了你想异步执行的计算,而不是如何创建一个线程来执行它。
- 就像使用高级语言:更抽象,更安全,更具表现力。
std::thread的问题
获取返回值困难
std::thread 的构造函数和 join() 方法都没有提供直接获取线程函数返回值的方式。你必须自己设计一套笨拙的机制来传递数据。
std::thread 的笨拙方式:
#include <thread>
#include <iostream>
int calculate_stuff() { return 42; }
int main() {
int result; // 需要一个外部变量来存储结果
// 必须通过引用把外部变量传进去,让线程函数修改它
std::thread t([&result] { result = calculate_stuff(); });
t.join(); // 等待线程结束
std::cout << "Result is: " << result << std::endl;
}
这种方法需要共享内存和手动同步,在复杂场景下很容易出错。
异常处理极其复杂
如果线程函数抛出了一个异常,而你没有在线程内部 try-catch 它,这个异常会导致 std::terminate 被调用,直接终止整个程序!它不会被 join() 的那个线程捕获。
void risky_task() {
throw std::runtime_error("Oops!");
}
int main() {
std::thread t(risky_task);
try {
t.join(); // 这个 try-catch 块完全没用!
} catch (const std::exception& e) {
// 永远不会执行到这里
std::cout << "Caught exception: " << e.what() << std::endl;
}
}
这个程序会直接崩溃。要正确处理,你必须在 risky_task 内部或传递给 thread 的 lambda 内部放置 try-catch,然后通过某种共享机制把异常信息传出来。这非常麻烦。
资源管理与进程调度
- 过度订阅 (Oversubscription):如果你创建的线程数量超过了 CPU 核心数,操作系统会花费大量时间在线程上下文切换上,反而降低了性能。
- 负载均衡:你很难手动实现一个高效的负载均衡系统,让所有 CPU 核心都保持忙碌。
joinvsdetach:你必须时刻记得对每个std::thread对象调用join或detach,否则它的析构函数会调用std::terminate终止程序。
基于任务的编程
C++ 标准库提供了一套基于 std::future 的工具,完美地解决了上述问题。
std::async 是这套工具中最简单、最直接的入口点。
std::async是一个任务启动器。你给它一个任务(一个函数或可调用对象),它会帮你(通常在另一个线程)异步地运行这个任务。std::future是一个结果接收器。std::async在启动任务后,会立即返回一个std::future对象。这个对象就像一张“凭证”或“期货”,它承诺在未来的某个时刻,你可以通过它来获取任务的执行结果。
std::future- 未来的凭证
std::future<T> 是一个模板类,其中 T 是异步任务的返回值类型。如果任务没有返回值,就使用 std::future<void>。
它提供了一个只能访问一次的、单向的通信频道,用于从一个线程(生产者/任务线程)向另一个线程(消费者/等待线程)传递数据。
核心操作:
get():- 这是
std::future最重要的方法。 - 调用
get()会阻塞当前线程,直到异步任务执行完毕。 - 任务完成后:
- 如果任务正常返回了一个值,
get()会返回这个值。 - 如果任务抛出了一个异常,
get()会在当前线程重新抛出这个异常。
- 如果任务正常返回了一个值,
get()只能被调用一次! 调用之后,future内部的状态就变为空了,再次调用会导致异常。
- 这是
wait():- 和
get()类似,wait()也会阻塞当前线程,直到异步任务完成。 - 但它不获取任务的结果,也没有返回值。
- 它的作用仅仅是“等待”。
- 你可以多次调用
wait()。
- 和
wait_for()/wait_until():- 这是带有超时的等待。
wait_for(duration)会等待指定的时长。如果任务在此期间完成,它会返回std::future_status::ready。如果超时,它会返回std::future_status::timeout。- 这对于避免无限期阻塞非常有用。
valid():- 检查
future是否与一个有效的共享状态相关联。 - 在
get()被调用之后,future就会变为invalid。
- 检查
std::future 的角色:它将启动任务的线程与需要任务结果的线程解耦。启动任务的线程可以立即获得一个 future 对象,然后继续执行其他工作,而不需要立即等待任务完成。
std::async- 轻松启动异步任务
std::async 是一个函数模板,它接受一个可调用对象(函数、lambda 等)和它的参数,然后异步地执行它。
基本语法:
std::future<ReturnType> fut = std::async(launch_policy, function, args...);
launch_policy(可选):这是一个非常重要的参数,它决定了任务的启动策略。function: 要异步执行的函数或可调用对象。args...: 传递给function的参数。
启动策略 (std::launch)
std::async 的行为很大程度上取决于你提供的启动策略:
std::launch::async(真异步):- 保证任务会在一个新的线程上立即开始执行。
- 这是你通常想要的“真”异步行为。
std::launch::deferred(延迟执行):- 任务不会立即启动。
- 它会被“延迟”,直到你对返回的
future调用.get()或.wait()时,才会在调用.get()或.wait()的那个线程上同步执行。 - 这实际上变成了一种“懒加载 (lazy evaluation)”机制。
std::launch::async | std::launch::deferred(默认策略):- 如果你不指定策略,这就是默认行为。
- 这给了标准库实现最大的自由度。它会自行决定是创建一个新线程(像
async),还是延迟执行(像deferred)。 - 这个决定可能基于当前的系统负载、可用的线程数量等因素。
- 陷阱:因为你不确定任务是否真的在另一个线程上运行,所以你不能依赖于它来执行那些必须并发运行的代码(比如一个需要并行更新UI的后台任务)。
最佳实践:除非你确实需要延迟执行,否则总是明确指定 std::launch::async,以确保你的代码行为是可预测的。
完整例子:
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
// 一个耗时的计算任务
long long heavy_calculation(int input) {
std::cout << "Calculation started...\n";
std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟耗时操作
if (input < 0) {
throw std::invalid_argument("Input cannot be negative");
}
return static_cast<long long>(input) * input;
}
int main() {
std::cout << "Main thread started.\n";
// --- 启动异步任务 ---
// 明确使用 std::launch::async 来保证在新线程中执行
std::future<long long> fut = std::async(std::launch::async, heavy_calculation, 100);
// --- 在主线程中做其他事情,而不被阻塞 ---
std::cout << "Main thread is doing other work while calculation runs in background.\n";
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Main thread has finished its other work.\n";
// --- 获取结果 ---
std::cout << "Main thread now needs the result.\n";
try {
// 调用 .get()。如果任务还没完成,这里会阻塞
long long result = fut.get();
std::cout << "Calculation finished! Result is: " << result << std::endl;
} catch (const std::exception& e) {
std::cout << "An exception was caught: " << e.what() << std::endl;
}
std::cout << "\n--- Demonstrating exception handling ---\n";
std::future<long long> fut_exception = std::async(std::launch::async, heavy_calculation, -1);
try {
fut_exception.get(); // .get() 会重新抛出任务中的异常
} catch (const std::exception& e) {
std::cout << "Caught exception from task: " << e.what() << std::endl;
}
std::cout << "Main thread finished.\n";
return 0;
}
输出:
Main thread started.
Main thread is doing other work while calculation runs in background.
Calculation started...
Main thread has finished its other work.
Main thread now needs the result.
Calculation finished! Result is: 10000
--- Demonstrating exception handling ---
Calculation started...
Caught exception from task: Input cannot be negative
Main thread finished.
main线程和heavy_calculation线程是并发执行的。fut.get()优雅地处理了等待和数据返回。fut_exception.get()优雅地处理了异常的捕获和重新抛出。
总结
| 特性 | std::async |
std::future |
|---|---|---|
| 角色 | 任务启动器 | 结果接收器 |
| 功能 | 异步地运行一个可调用对象,并返回一个 future。 |
提供一个访问异步操作结果的通道。 |
| 核心操作 | std::async(policy, func, args...) |
get(), wait(), wait_for() |
| 优点 | 自动管理线程,简化了异步调用的语法。 | 干净地处理返回值和异常,解耦了调用者和执行者。 |
std::async 和 std::future 共同构成了一个强大、高级的并发编程模型。它们将你从手动管理 std::thread、共享数据、互斥锁和异常传递的泥潭中解放出来,让你能够以一种更声明式、更安全的方式来编写并发代码。
item36:如果异步性是必需的,请指定 std::launch::async
std::async 是一个非常方便的工具,可以异步地运行一个任务。然而,它的默认启动策略可能会让你的任务并非真正地异步执行,而是在你请求结果时同步地、延迟地执行。
核心论点:如果你调用 std::async 的目的是为了让一个任务并发地 (concurrently) 在另一个线程上运行(例如,为了利用多核 CPU,或者为了不阻塞当前线程),那么你必须明确地将 std::launch::async 作为第一个参数传递给它。
std::async 的函数签名大致如下:
template<class Function, class... Args>
std::future<...> async( std::launch policy, Function&& f, Args&&... args );
template<class Function, class... Args>
std::future<...> async( Function&& f, Args&&... args ); // 不带策略的重载版本
关键在于不带策略的重载版本的行为。当你像这样调用它时:
auto fut = std::async(my_task);
这等价于:
auto fut = std::async(std::launch::async | std::launch::deferred, my_task);
std::launch::async | std::launch::deferred 这个默认策略给了 C++ 标准库的实现(特别是其内部的线程调度器)完全的自由裁量权,让它可以从以下两种行为中任选其一:
-
std::launch::async行为:任务被异步地在一个新的(或线程池中的)线程上执行。这实现了真正的并发。
-
std::launch::deferred行为:任务被延迟 (deferred)。它不会立即在任何线程上开始执行。
它会等到你对返回的
std::future对象调用.get()或.wait()时,才会在调用.get()或.wait()的那个线程上同步地执行。在这种情况下,根本没有发生任何并发。调用线程会被阻塞,直到任务执行完毕。
为什么这个默认行为很危险?
因为你无法预测你的任务会以哪种方式执行。这取决于标准库的实现、当前的系统负载、可用的线程数等多种因素。
这种不确定性会导致一系列严重的问题。
对线程局部存储的依赖失效
如果你的任务依赖于线程局部存储(TLS),而它恰好被延迟执行了,那么它将在调用 .get() 的线程上运行。这个线程的 TLS 可能完全不是你期望的那个。
thread_local int tls_var = 0;
void task() {
tls_var = 42; // 修改任务线程的 TLS
}
int main() {
auto fut = std::async(task); // 默认策略
// ...
fut.wait(); // 假设这里 task 被延迟执行,在 main 线程上运行
// 此时,是 main 线程的 tls_var 变成了 42,而不是某个后台线程的。
// 这可能完全违背了你的设计意图。
}
基于超时的wait变得毫无意义
如果你使用 wait_for 或 wait_until 来实现带超时的逻辑,这个逻辑可能会因为延迟执行而完全失效。
auto fut = std::async(very_long_task);
// 尝试等待 10 毫秒
if (fut.wait_for(std::chrono::milliseconds(10)) == std::future_status::deferred) {
// 如果任务被延迟,wait_for 会立即返回 deferred
// very_long_task 根本还没有开始执行!
std::cout << "Task is deferred.\n";
}
当你对一个延迟任务的 future 调用 wait_for 时,它会立即返回 std::future_status::deferred。你的超时逻辑形同虚设,你无法判断任务是否真的“超时”了。
更糟糕的是,如果你接下来调用 .get(),你会被无条件地阻塞,直到 very_long_task 执行完毕,无论它需要多长时间
任务可能永远都不会被执行
这是最隐蔽的陷阱。如果你使用默认策略,并且从不对返回的 future 调用 .get() 或 .wait(),那么那个被延迟的任务可能永远都不会被执行!
// "即发即忘" (fire-and-forget) 的错误用法
void fire_and_forget() {
std::async(some_important_task); // 默认策略,返回的 future 被立刻丢弃
}
如果 some_important_task 被调度器决定延迟执行,但返回的 future 立即被销毁了,那么就再也没有机会去调用 .get() 或 .wait() 来触发它了。这个重要任务就这么无声无息地消失了。
item37:使 std::thread 对象在所有路径最后都不可结合
- 可合并:线程正在执行,或者已经完成但其资源(包括返回值、异常)尚未被收集。一个可合并的线程必须在它的
std::thread对象被销毁前,被join()或detach()。 - 不可合并:线程已经被
join()(等待其完成并收集资源) 或detach()(让其独立运行,无需等待)。或者,它是一个默认构造的std::thread对象(没有关联任何执行流)。
问题:如果一个可合并的 std::thread 对象在被 join() 或 detach() 之前就被销毁了(例如,因为它离开了作用域),C++ 标准库会调用 std::terminate() 来终止整个程序。这通常不是你想要的行为,因为这会绕过正常的析构函数调用,导致资源泄漏。
Item 37 的核心论点:你必须确保,无论线程函数是正常结束、提前返回,还是在线程函数内部抛出异常,你的 std::thread 对象在离开作用域时都不会是可合并的状态。
#include <iostream>
#include <thread>
#include <vector>
void doWork() {
std::cout << "Thread is working...\n";
// ... 模拟一些工作 ...
// throw std::runtime_error("Exception from thread!"); // 甚至可以抛异常
}
int main() {
std::cout << "Main: Starting thread in a scope.\n";
{
std::thread t(doWork); // 创建一个可合并的线程
// ... 假设这里有一些逻辑 ...
// 如果这里提前 return; 或者抛出异常,那么 t 就没有被 join/detach
} // <--- t 离开作用域,其析构函数被调用
// 此时 t 是可合并的,但它被销毁了。
// std::terminate() 被调用,程序崩溃!
std::cout << "Main: After thread scope. This line won't be reached.\n";
return 0;
}
为什么会崩溃?
std::thread t(doWork);创建了一个std::thread对象t,它关联了一个正在运行的线程。此时t.joinable()返回true。t在}处离开作用域。std::thread类的析构函数被调用。std::thread的析构函数会检查*this是否是可合并的。如果*this是可合并的,它会调用std::terminate()。- 由于
t是可合并的,程序终止。
使用 RAII 包装器
这是最健壮、最 C++ 风格的解决方案。创建一个简单的类,它在构造时接管 std::thread 对象,在析构时自动调用 join() 或 detach()。
#include <thread>
#include <iostream>
#include <functional> // For std::function
// 一个简单的 RAII 包装器
class ThreadGuard {
public:
// 构造函数接管一个 std::thread 对象
explicit ThreadGuard(std::thread t) : t_(std::move(t)) {
if (!t_.joinable()) {
throw std::runtime_error("Thread not joinable!");
}
}
// 析构函数:在 ThreadGuard 对象销毁时自动 join
~ThreadGuard() {
if (t_.joinable()) {
std::cout << "ThreadGuard: Joining thread.\n";
t_.join();
}
}
// 禁止拷贝和移动,确保独占所有权
ThreadGuard(const ThreadGuard&) = delete;
ThreadGuard& operator=(const ThreadGuard&) = delete;
private:
std::thread t_;
};
void doWorkSafe() {
std::cout << "Thread is working safely...\n";
// ...
// throw std::runtime_error("Exception from safe thread!");
}
int main() {
std::cout << "Main: Starting thread in a scope with ThreadGuard.\n";
{
ThreadGuard g(std::thread(doWorkSafe)); // 线程被 ThreadGuard 管理
// ... 如果这里提前 return; 或者抛出异常,ThreadGuard 也会正确处理 ...
// throw std::runtime_error("Exception from main scope!");
} // <--- g 离开作用域,ThreadGuard 的析构函数被调用,自动 join 线程
std::cout << "Main: After thread scope with ThreadGuard. Program continues.\n";
return 0;
}
- RAII 的力量:无论
ThreadGuard对象如何离开作用域(正常退出、提前return、抛出异常),它的析构函数都会被调用,从而保证t_.join()被执行。 std::move(t):构造函数需要移动传入的std::thread对象的所有权,因为std::thread是不可拷贝的 (Item 18)。
手动 try-catch 和 join/detach
如果你不使用 RAII 包装器,你就必须手动在所有可能的地方处理 join 或 detach。这非常容易出错。
void doWorkManual() { /* ... */ }
int main() {
std::thread t(doWorkManual);
try {
// ... 业务逻辑 ...
t.join(); // 正常路径
// ...
// return 0; // 如果这里返回,t 已经 join 了
} catch (...) { // 捕获所有异常
if (t.joinable()) {
t.join(); // 异常路径
}
throw; // 重新抛出异常
}
if (t.joinable()) { // 再次检查,以防万一
t.join();
}
return 0;
}
显式 detach()
如果你确定你的主程序不关心线程的完成时间、返回值或异常(即“即发即忘”),你可以使用 detach()。
void backgroundTask() { /* ... */ }
int main() {
std::thread t(backgroundTask);
t.detach(); // 线程将独立运行,程序不再关心它的生命周期
// ... main thread continues immediately ...
// 注意:如果 main 线程比 backgroundTask 先结束,
// backgroundTask 可能会在 main 结束前运行,也可能被操作系统终止。
// 如果 backgroundTask 内部抛异常,并且没人捕获,仍然可能导致 std::terminate。
std::cout << "Main thread detached backgroundTask.\n";
return 0;
}
- 优点:简单。
- 缺点:
- 无法获取返回值或异常:一旦
detach,你就失去了与线程的所有同步能力。 - 资源泄漏风险:如果
backgroundTask内部抛异常且未被捕获,仍会调用std::terminate。 - 程序提前结束:如果主程序在分离线程完成前结束,分离线程可能不会有时间完成它的工作。
- 无法获取返回值或异常:一旦
总结与指导方针
std::thread的析构函数很危险:如果一个可合并的std::thread对象在析构时仍是可合并的,程序会调用std::terminate()。- RAII 是最佳实践:使用一个 RAII 类(如
ThreadGuard)来包装std::thread对象,并在析构函数中自动调用join()或detach()。这能保证在所有代码路径(包括异常)上,线程都被正确处理。 std::async是更好的抽象:这个条款的复杂性进一步说明了 Item 35 的观点:尽量使用std::async等基于任务的 API。它们在底层已经为你处理了future的get()/wait(),从而解决了std::thread的join需求和异常传递。- 谨慎使用
detach():只有在你明确不关心线程的完成状态,且线程内部能够完全处理自己的所有逻辑(包括异常)时,才考虑使用detach()。
遵循 Item 37 的建议,可以显著提高你直接使用 std::thread 时的代码健壮性和安全性,避免意外的程序终止。
item38:关注不同线程的句柄析构行为
这个条款是 Item 37 (关于 std::thread 的 join/detach 规则) 的一个重要补充。它指出,虽然 std::thread 的析构行为在 C++ 标准中是确定的(如果可合并则调用 std::terminate),但其他并发 API 中的线程句柄类 (thread handle classes) 在析构时可能有不同且不兼容的行为。
当你使用 C++ 标准库之外的并发库(如 POSIX pthreads、Windows Threads、或者一些第三方库)时,你不能想当然地认为它们的线程句柄类在析构时会和 std::thread 一样。它们的默认析构行为可能完全不同,这可能导致资源泄漏、程序卡死或未定义行为。
std::thread 的析构行为
我们已经知道,std::thread 的析构函数行为是严格定义且非常激进的:
- 如果
std::thread对象是可合并的 (joinable() == true),它的析构函数会调用std::terminate()。 - 如果
std::thread对象是不可合并的 (joinable() == false),它的析构函数会正常执行。
这种行为的目的是为了强制程序员显式地处理线程的生命周期,要么等待它完成 (join()),要么让它独立运行 (detach())。它防止了线程在后台默默运行,但其控制对象却已销毁的潜在混乱局面
其他并发 API 的线程句柄行为
许多操作系统和第三方库都有自己的线程 API,它们通常提供一个表示线程的“句柄”或“ID”。这些句柄类的析构行为可能与 std::thread 大相径庭。
POSIX pthreads (C 语言风格 API)
POSIX 线程库 (pthread) 是 Linux/Unix 系统上的标准线程 API。它没有提供 C++ 风格的 RAII 线程句柄类,而是使用 pthread_t 类型和 C 函数。
pthread_t tid;: 这是一个线程 ID,而不是一个 RAII 对象。pthread_create(...): 创建线程。pthread_join(tid, ...): 等待线程完成并回收资源。pthread_detach(tid): 分离线程。- 没有自动析构行为:
pthread_t只是一个数值类型,它没有析构函数。如果你忘记调用pthread_join或pthread_detach,线程资源将永远不会被操作系统回收,导致线程资源泄漏。操作系统会认为线程还在运行,并保留其栈和上下文,直到进程结束。
问题:与 std::thread 的强制终止不同,这里的问题是静默的资源泄漏。程序不会崩溃,但会慢慢耗尽操作系统资源。
Windows Threads (C 语言风格 API)
Windows 线程 API 使用 HANDLE 类型。
HANDLE hThread;: 这是一个句柄。CreateThread(...): 创建线程。WaitForSingleObject(hThread, ...): 等待线程完成。CloseHandle(hThread): 关闭句柄。CloseHandle的双重含义:在 Windows API 中,CloseHandle不仅仅是回收句柄资源,它也常常被用作回收线程资源的关键一步(如果没有WaitForSingleObject等待线程结束,可能导致资源泄漏)。如果你忘记调用CloseHandle,同样会导致句柄泄漏和线程资源泄漏。
问题:同样是静默的资源泄漏,但其管理模型可能比 POSIX 线程更复杂。
Solution:统一的 RAII 管理
Item 38 的核心建议是:无论你使用什么底层线程 API,都应该用一个 C++ 风格的 RAII 包装器来封装它,并明确定义其析构行为。
这使得你的代码与底层 API 的具体规则解耦,并能以统一、可预测的方式管理线程资源。
一个带移动功能的 RAII
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
enum class Policy
{
Join,
Detach
};
class ThreadWrapper
{
public:
ThreadWrapper(std::thread t, Policy pol) : t_(std::move(t)), pol_(pol)
{
if (!t_.joinable())
{
throw std::runtime_error("thread not joinable!");
}
}
~ThreadWrapper()
{
if (t_.joinable())
{
if (pol_ == Policy::Join)
{
std::cout << "join\n";
t_.join();
}
else
{
std::cout << "detach\n";
t_.detach();
}
}
}
std::thread& get(){ return t_; };
ThreadWrapper(const ThreadWrapper&) = delete;
ThreadWrapper& operator=(const ThreadWrapper&) = delete;
ThreadWrapper(ThreadWrapper&&) noexcept = default;
ThreadWrapper& operator=(ThreadWrapper&& other) noexcept //注意这里的移动函数!
{
if (this == &other) return *this;
if (t_.joinable())
{
t_.join();
}
t_ = std::move(other.t_);
pol_ = std::move(other.pol_);
std::cout << "move!\n";
return *this;
}
private:
std::thread t_;
Policy pol_;
};
void task()
{
std::cout << "task running...\n";
}
int main() {
{
ThreadWrapper tw1(std::thread(task), Policy::Join);
ThreadWrapper tw2(std::thread(task), Policy::Join);
tw1 = std::move(tw2);
}
}
需要注意的是,移动函数不能是default。
假如移动函数是default:
tw1.t_ = std::move(tw2.t_); 这一步:
这调用了 std::thread 的移动赋值运算符。std::thread的移动赋值运算符的语义是:
this(tw1.t_) 首先检查自己是否是 joinable 的。- 如果
this(tw1.t_) 是 joinable 的,它会调用std::terminate()来终止程序! (这是std::thread的一个非常重要的规则)。 - 如果
this(tw1.t_) 不是 joinable 的,它会接管other(tw2.t_) 的线程所有权,然后other(tw2.t_) 变成一个没有关联线程的状态。
tw1.t_ 在执行 tw1 = std::move(tw2) 之前是 joinable 的!因为它拥有一个正在运行的线程。
所以,程序在执行 tw1.t_ = std::move(tw2.t_); 的第一步时,就会因为 tw1.t_ 是 joinable 的而调用 std::terminate(),导致崩溃。
为什么 std::thread 的移动赋值运算符这么设计?
这个设计是为了强制 RAII 原则和防止线程泄露。std::thread 的设计者认为,如果一个 std::thread 对象已经关联了一个活动的线程,但在赋值操作中被覆盖了,那么这个旧的线程就失去了它的“所有者”。这个旧线程的命运就变得模糊不清了。
为了避免这种混乱和潜在的资源泄漏,std::thread 采取了最激进但最安全的策略:如果赋值的目标 std::thread 仍然是 joinable 的,这被视为一个编程错误,程序立即终止。它强制你必须先显式地处理旧线程(join() 或 detach()),然后才能进行赋值操作。
item39:考虑对于单次事件通信使用void
在传统的并发编程中,要实现这种“信号/等待”机制,我们通常会使用条件变量 (Condition Variables)。然而,条件变量的使用是出了名的复杂和容易出错:
- 它必须与一个互斥锁 (Mutex) 配合使用。
- 它可能会有虚假唤醒 (spurious wakeups),这意味着等待的线程可能在没有收到通知的情况下被唤醒,所以你必须在一个
while循环中检查一个共享的标志位。 - 你需要手动管理互斥锁的加锁和解锁,以及标志位的读写。
Item 39 的核心论点:对于一次性 (one-shot) 的事件通知,使用 std::promise 和 std::future<void> 的组合,是一种比条件变量更简单、更安全、也可能更高效的替代方案。
条件变量的复杂性
让我们先看一个使用条件变量的经典生产者-消费者(或信号-等待)模式,来感受一下它的复杂性。
场景:一个数据准备线程(生产者)需要通知一个数据处理线程(消费者)数据已经准备好了。
使用 std::condition_variable 的代码
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool data_ready = false; // 共享的标志位
// 等待线程(消费者)
void waiting_thread() {
std::cout << "Waiting thread: Waiting for data...\n";
// 1. 加锁
std::unique_lock<std::mutex> lock(mtx);
// 2. 在循环中等待,防止虚假唤醒
// wait 会自动解锁,然后等待。被唤醒后,它会重新加锁并检查条件。
cv.wait(lock, [] { return data_ready; });
// 3. 条件满足,继续执行
std::cout << "Waiting thread: Data is ready! Processing...\n";
// ... process data ...
}
// 信号线程(生产者)
void signaling_thread() {
std::cout << "Signaling thread: Preparing data...\n";
std::this_thread::sleep_for(std::chrono::seconds(2));
// 4. 加锁以保护共享标志位
{
std::lock_guard<std::mutex> lock(mtx);
data_ready = true;
std::cout << "Signaling thread: Data prepared. Notifying...\n";
} // 锁在这里释放
// 5. 发送通知
cv.notify_one();
}
int main() {
std::thread t1(waiting_thread);
std::thread t2(signaling_thread);
t1.join();
t2.join();
}
这段代码虽然能工作,但包含了大量的样板代码:一个互斥锁、一个条件变量、一个共享的布尔标志,以及复杂的加锁、解锁和循环等待逻辑。这对于一个简单的一次性通知来说,实在是太复杂了
std::promise和std::future<void>
std::promise 和 std::future 对提供了一个更高级、更抽象的通信模型。
std::promise: 生产者端。它承诺 (promises) 在未来某个时刻会提供一个值(或一个信号)。std::future: 消费者端。它持有这个承诺的未来 (future),并可以等待这个承诺被兑现。
当事件本身没有关联的数据,只是一个纯粹的“好了,你可以继续了”的信号时,我们就可以使用 void 类型的 promise 和 future。
使用 std::promise/std::future<void> 的代码:
#include <iostream>
#include <thread>
#include <future>
// 等待线程
void waiting_thread_future(std::future<void>& fut) {
std::cout << "Waiting thread: Waiting for signal...\n";
// 1. 等待 promise 被设置。fut.wait() 或 fut.get() 都会阻塞。
// 这里没有互斥锁,没有循环,没有虚假唤醒!
fut.get(); // get() on a std::future<void> waits and returns void.
std::cout << "Waiting thread: Signal received! Continuing...\n";
}
// 信号线程
void signaling_thread_future(std::promise<void>& prms) {
std::cout << "Signaling thread: Doing some work...\n";
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "Signaling thread: Work done. Sending signal...\n";
// 2. 兑现承诺,发送信号。
prms.set_value();
}
int main() {
std::promise<void> p;
std::future<void> f = p.get_future();
// 将 promise 和 future 分别传递给两个线程
// std::ref(f): 使用引用来传递f
// std::thread 总是试图按值拷贝参数到新线程的内部存储中, 但是std::future 和 std::promise 是不可拷贝的
std::thread t1(waiting_thread_future, std::ref(f));
// promise 是只能移动的,所以需要 std::move
std::thread t2(signaling_thread_future, std::ref(p));
t1.join();
t2.join();
}
- 在
main中,我们创建了一个std::promise<void> p。 - 我们从
p中获取一个关联的std::future<void> f。p和f构成了一个通信频道。 waiting_thread_future拿到了f,并调用f.get()。这会阻塞该线程,直到p兑现它的承诺。signaling_thread_future拿到了p。在完成工作后,它调用p.set_value()。p.set_value()的调用会解除f.get()的阻塞,waiting_thread_future线程被唤醒并继续执行
何时仍然需要条件变量?
尽管 promise/future 非常适合一次性通信,但条件变量在某些场景下仍然是必要的:
- 重复性/循环性事件:当一个生产者需要多次通知一个或多个消费者时(比如在一个循环中不断生产数据),条件变量是更合适的工具。
promise只能被设置一次。 - 一个生产者对多个消费者 (广播):
std::condition_variable::notify_all()可以一次性唤醒所有等待的线程。而一个std::future只能被一个线程get()。虽然有std::
item40:对并发使用 std::atomic,对特殊内存使用 volatile
这个条款旨在澄清 C++ 中两个经常被混淆、甚至滥用的关键字:std::atomic 和 volatile。它们都与“不寻常”的内存访问有关,但它们解决的是完全不同的问题。错误地将它们互换使用会导致非常严重的 bug。
std::atomic:是并发编程 (Concurrency) 的工具。它用于在多个线程之间同步数据访问,确保操作的原子性 (atomicity) 和建立内存顺序 (memory ordering),从而防止数据竞争 (data races)。volatile:是与特殊内存 (Special Memory) 通信的工具。它告诉编译器,某个变量的值可能会在程序的“正常执行流程”之外被意外地改变,因此编译器不能对这个变量的读写操作进行任何优化(如缓存到寄存器、重排指令等)。
一句话总结:atomic 解决了多线程问题,volatile 解决了编译器优化问题。
std::atomic
std::atomic<T> 是一个模板类,它包装了一个类型 T 的值,并保证对这个值的所有操作都是原子的。
什么是原子操作? 一个操作是原子的,意味着它在执行过程中是不可分割的。从其他线程的角度看,这个操作要么还没开始,要么已经全部完成,绝不会看到它“执行到一半”的中间状态。
例:一个安全的计数器
#include <atomic>
std::atomic<int> atomic_counter = 0; // 使用 std::atomic<int>
void atomic_increment() {
for (int i = 0; i < 100000; ++i) {
atomic_counter++; // 这是原子操作!
}
}
atomic_counter++ 会被编译成一条特殊的、不可中断的 CPU 指令(如 LOCK INC on x86)。这保证了“读-改-写”的整个过程在一个不可分割的步骤中完成,从而彻底消除了数据竞争。
std::atomic 的另一个重要作用:内存顺序
std::atomic 操作不仅仅是原子的,它们还充当了内存屏障 (memory fences),用于控制编译器和 CPU 对内存操作的重排 (reordering)。这确保了一个线程的写入对其他线程是可见的。volatile 完全没有这个能力。
volatile
volatile 的唯一作用是抑制编译器优化。
它告诉编译器:“你(编译器)不知道这个变量的所有情况。它的值可能随时被我看不见的东西改变。所以,每次我读取这个变量时,你必须老老实实地从它的内存地址去读;每次我写入这个变量时,你必须老老实实地把它写回内存地址。不要做任何缓存或重排的聪明事。”
什么东西是“编译器看不见的”?
-
内存映射的硬件 I/O 端口 (Memory-Mapped I/O):这是
volatile最主要、最正当的用途。一个硬件设备(如串口)的状态寄存器可能被映射到某个特定的内存地址。volatile uint8_t* const UART_STATUS_REGISTER = (uint8_t*)0x1234; // 等待,直到硬件设置了“发送就绪”位 while ((*UART_STATUS_REGISTER & 0x80) == 0) { // 空循环 }如果没有
volatile,聪明的编译器会看到:循环体内没有修改*UART_STATUS_REGISTER,所以它是一个循环不变量。编译器可能会把*UART_STATUS_REGISTER的值只读取一次,缓存到一个寄存器中,然后让while循环永远检查这个寄存器的值。这将导致一个无限循环,因为程序永远无法看到硬件在外部对这个内存地址的修改。volatile强制编译器在每次循环时都重新从内存地址0x1234读取值。 -
多线程中的共享变量(错误用法!): 有些程序员错误地认为,既然多个线程会改变一个变量,那它也属于“在程序流程之外被意外改变”,所以应该用
volatile。 这是完全错误的!
volatile不能保证原子性。volatile int counter; counter++;仍然会被分解为“读-改-写”,仍然会发生数据竞争。volatile不能阻止 CPU 指令重排,也不能提供多核之间的内存可见性保证。一个 CPU 核心的写入可能仍然停留在它自己的缓存中,而没有被其他核心看到。volatile只解决了编译器的优化问题,没有解决硬件(多核 CPU) 层面上的并发问题。
item41:对于移动成本低且总是会被拷贝的可拷贝形参,考虑按值传递
传统智慧 (Pre-C++11):
当你需要一个函数的输入参数,并且不打算在函数内修改它时,最佳方式是按 const 引用传递。
void func(const std::string& s);
这避免了创建参数副本的开销,特别是对于 std::string、std::vector 等大型对象。
按值传递的好处
Item 41 提出的新思路 (Post-C++11):
如果一个函数最终需要拥有这个参数的一个副本(例如,要把它存为一个成员变量),并且这个参数的类型是移动成本低廉的(比如 std::string),那么直接按值传递 (pass-by-value) 可能更高效。
// 传统方式
void setName(const std::string& newName) {
name_ = newName; // 拷贝操作
}
// Item 41 建议的方式
void setName(std::string newName) { // 按值传递
name_ = std::move(newName); // 移动操作
}
| 场景 | 传统方式 (pass-by-const-ref) |
按值传递 (pass-by-value) | 谁更优? |
|---|---|---|---|
| 传入左值 | 1 次拷贝 | 1 次拷贝 + 1 次移动 | 传统方式略优 (少一次廉价的移动) |
| 传入右值 | 1 次拷贝 | 1 次移动 (优化后) | 按值传递方式显著更优! |
结论:
- 按值传递在处理右值参数时,将昂贵的拷贝操作优化成了一次廉价的移动操作,性能提升巨大。
- 在处理左值参数时,它的成本略高于传统方式(多了一次移动),但因为移动通常非常廉价,这点性能损失可以忽略不计
何时不应该使用按值传递?
-
函数总是需要一个副本: 如果函数只是“观察”参数,而不需要存储它,那么按
const引用传递永远是最佳选择。// 只是打印,不需要副本,应该用 const ref void printName(const std::string& s); -
移动操作必须廉价: 对于
std::string,std::vector,std::unique_ptr等管理堆内存的类型,移动操作非常廉价(只需交换几个指针/整数)。但对于像std::array这样的类型,它的数据直接存储在对象内部,移动和拷贝的成本完全一样。对std::array使用按值传递只会增加开销。 -
参数类型是可拷贝的: 如果参数是只能移动的类型(如
std::unique_ptr),你必须按值传递(或者右值引用传递T&&)才能接收它。 -
切片问题 (Slicing Problem): 如果你在处理继承体系,按值传递一个基类类型的参数会导致对象切片——派生类特有的部分会丢失。在这种情况下,你应该传递指针或引用(通常是智能指针)。
item42:考虑使用置入代替插入
这个条款是关于如何向 STL 容器中添加元素的一个重要的性能优化建议。C++11 为几乎所有容器引入了 emplace_* 系列的成员函数(如 emplace_back, emplace, emplace_hint),它们在很多情况下能比传统的 push_* 或 insert 函数更高效
传统的插入 (insert, push_back) 方法的工作流程是:
- 在容器外部创建一个完整的对象(实参)。
- 将这个创建好的对象拷贝 (copy) 或移动 (move) 到容器内部。
emplace 方法的工作流程是:
- 将构造对象所需的参数 (arguments) 直接传递给
emplace函数。 - 函数会在容器管理的内存中,就地 (in-place) 使用这些参数来直接构造对象。
核心区别:emplace 避免了在容器外部创建临时对象,以及随后将其拷贝或移动到容器内的过程。它把“创建对象”这一步直接在容器的最终存储位置上完成了。
emplace_back vs. push_back (以 std::vector 为例)
这是最能体现 emplace 优势的经典例子。
假设我们有一个 Widget 类:
#include <iostream>
#include <string>
class Widget {
public:
Widget(int id, const std::string& name) : id_(id), name_(name) {
std::cout << " Widget(" << id_ << ", " << name_ << ") constructed.\n";
}
Widget(const Widget& other) : id_(other.id_), name_(other.name_) {
std::cout << " Widget copied.\n";
}
Widget(Widget&& other) noexcept : id_(other.id_), name_(std::move(other.name_)) {
std::cout << " Widget moved.\n";
}
private:
int id_;
std::string name_;
};
现在,我们用 push_back 和 emplace_back 分别向 std::vector<Widget> 中添加元素。
使用 push_back
场景 A: 传入左值 (lvalue)
std::vector<Widget> widgets;
Widget w(1, "Fido");
std::cout << "Pushing back lvalue:\n";
widgets.push_back(w);
输出:
Widget(1, Fido) constructed.
Pushing back lvalue:
Widget copied.
过程: push_back 接收一个 const Widget&。它在 vector 内部通过拷贝构造函数创建了一个 w 的副本。成本:1 次拷贝。
场景 B: 传入右值 (rvalue)
std::cout << "Pushing back rvalue:\n";
widgets.push_back(Widget(2, "Spot"));
输出:
Pushing back rvalue:
Widget(2, Spot) constructed.
Widget moved.
过程:
Widget(2, "Spot")在push_back的调用点创建了一个临时对象 (右值)。push_back有一个接受右值引用的重载push_back(Widget&&)。它在vector内部通过移动构造函数将这个临时对象“移动”进去。 成本:1 次构造 + 1 次移动。
使用 emplace_back
emplace_back 是一个可变参数模板,它将收到的所有参数完美转发 (perfectly forwards) 给 Widget 的构造函数。
std::cout << "Emplacing back:\n";
widgets.emplace_back(3, "Darla"); // 直接传递构造函数的参数
输出:
Emplacing back:
Widget(3, Darla) constructed.
过程:
emplace_back在vector内部预留出可以容纳一个Widget对象的内存空间。- 它在这块内存上,使用你传递的参数
(3, "Darla")直接调用Widget的构造函数Widget(int, const std::string&)来就地构造一个Widget对象。
成本:只有 1 次构造。没有创建任何临时对象,也没有任何拷贝或移动。
| 操作 | 成本 |
|---|---|
push_back(lvalue) |
1 次拷贝 |
push_back(rvalue) |
1 次构造 + 1 次移动 |
emplace_back(args...) |
只有 1 次构造 |
结论:emplace_back 永远不会比 push_back 更差,并且在很多情况下(特别是当参数可以直接用于构造时)效率更高。因为它避免了创建临时对象和随后的移动/拷贝操作
何时 emplace 的优势不明显或需要注意?
传入的对象类型与容器元素类型完全相同
如果你传入的对象已经是容器所需要的类型,那么 emplace 和 push 的行为几乎没有区别。
Widget w(4, "Rover");
widgets.push_back(w); // 1 次拷贝
widgets.emplace_back(w); // 同样是 1 次拷贝
在这种情况下,emplace_back(w) 也会调用 Widget 的拷贝构造函数来就地构造,所以成本和 push_back 是一样的。
widgets.push_back(std::move(w)); // 1 次移动
widgets.emplace_back(std::move(w)); // 同样是 1 次移动
同样,如果传入右值,两者都会调用移动构造函数,成本也一样。
窄化转换 (Narrowing Conversions) 和 explicit 构造函数
这是一个重要的安全问题。push_back 在类型匹配上更严格,而 emplace_back 由于完美转发,可能会允许一些危险的隐式类型转换。
std::vector<int> v;
// v.push_back(10.5); // 编译警告或错误,因为 double -> int 是窄化转换
v.emplace_back(10.5); // OK!编译通过,10.5 被隐式转换为 10
push_back 通常需要一个与容器元素类型匹配(或可安全转换)的对象。而 emplace_back 会直接尝试用你给的参数去调用构造函数,如果存在一个 int(double) 的构造函数,它就会被调用。
同样,如果一个构造函数是 explicit 的,push_back 可能无法通过隐式转换来调用它,但 emplace_back 因为是直接调用,所以可以成功。
struct Foo {
explicit Foo(int) {}
};
std::vector<Foo> foos;
// foos.push_back(10); // 编译错误!不能从 int 隐式转换为 Foo
foos.emplace_back(10); // OK!直接调用 explicit Foo(10)
虽然这有时很方便,但也绕过了 explicit 关键字设置的“安全护栏”,可能隐藏 bug。
资源管理和异常安全
在一些罕见的情况下,比如在 std::vector 扩容时,或者向 std::map 中 emplace 一个可能已存在的键时,emplace 可能会构造一个最终不会被插入容器的对象,然后销毁它。如果对象的构造和析构成本很高,这可能会抵消 emplace 带来的优势。然而,这种情况非常少见,通常不需要过度担心。
总结与指导方针
- 优先考虑
emplace:当你向容器中添加新元素时,应该默认使用emplace_\*系列函数。它们在性能上至少和push_*/insert一样好,并且常常更好。 - 传递构造函数参数:
emplace的最大优势体现在你直接传递构造对象所需的参数时,这避免了创建临时对象。 - 注意类型安全:要意识到
emplace在类型转换上比insert更“宽容”。它会直接调用构造函数,可能会绕过explicit的限制或执行你不期望的窄化转换。 - 清晰性:在绝大多数情况下,
emplace不仅更高效,代码意图也同样清晰:container.emplace_back(arg1, arg2);明确表示了“在容器末尾用arg1和arg2构造一个新元素”。
总而言之,养成使用 emplace 的习惯是编写高效、现代 C++ 代码的一个好标志。你只需要对它在类型安全方面的细微差别保持警惕即可。
————————————————完——————————————————-